解决Spring Cloud Gateway获取request body为null
问题1:无法获取body内容
问题原因分析
在使用过程中碰到过滤器中获取的内容一直都是空的,尝试了网上的各种解析body内容的方法,但是得到结果都是一样,死活获取不到body数据,一度很崩溃。后来进行了各种尝试,最终发现使用不同的spring boot版本和spring cloud版本,对结果影响很大。
最佳实践
方案1:降低版本
springboot版本:2.0.5-RELEASE
springcloud版本:Finchley.RELEASE
使用以上的版本会报以下的错误:
java.lang.IllegalStateException: Only one connection receive subscriber allowed.
原因在于spring boot在2.0.5版本如果使用了WebFlux就自动配置HiddenHttpMethodFilter过滤器。查看源码发现,这个过滤器的作用是,针对当前的浏览器一般只支持GET和POST表单提交方法,如果想使用其他HTTP方法(如:PUT、DELETE、PATCH),就只能通过一个隐藏的属性如(_method=PUT)来表示,那么HiddenHttpMethodFilter的作用是将POST请求的_method参数里面的value替换掉http请求的方法。但是这就导致已经读取了一次body,导致后面的过滤器无法读取body。解决方案就是可以自己重写HiddenHttpMethodFilter来覆盖原来的实现,实际上gateway本身就不应该做这种事情,原始请求是怎样的,转发给下游的请求就应该是怎样的。
@Bean
public HiddenHttpMethodFilter hiddenHttpMethodFilter() {
return new HiddenHttpMethodFilter() {
@Override
public Mono<Void> filter(ServerWebExchange exchange, WebFilterChain chain) {
return chain.filter(exchange);
}
};
}
这个方案也是gateway官方开发者目前所提出的解决方案。
方案2:不降低版本,缓存body内容
springboot版本:2.1.5-RELEASE
springcloud版本:Greenwich.SR1
在较高版本中,上面的方法已经行不通了,可以自定义一个高优先级的过滤器先获取body内容并缓存起来,解决body只能读取一次的问题。具体解决方案见问题2。
问题2:body只能读取一次
这个问题网上主要的解决思路就是获取body之后,重新封装request,然后把封装后的request传递下去。思路很清晰,但是实现的方式却千奇百怪。在使用的过程中碰到了各种千奇百怪的问题,比如说第一次请求正常,第二次请求报400错误,这样交替出现。最终定位原因就是我自定义的全局过滤器把request重新包装导致的,去掉就好了。鉴于踩得坑比较多,下面给出在实现过程中笔者认为的最佳实践。
核心代码
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferUtils;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpRequestDecorator;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
/**
* 这个过滤器解决body不能重复读的问题
* 实际上这里没必要把body的内容放到attribute中去,因为从attribute取出body内容还是需要强转成
* Flux<DataBuffer>,然后转换成String,和直接读取body没有什么区别
*/
@Component
public class CacheBodyGlobalFilter implements Ordered, GlobalFilter {
// public static final String CACHE_REQUEST_BODY_OBJECT_KEY = "cachedRequestBodyObject";
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
if (exchange.getRequest().getHeaders().getContentType() == null) {
return chain.filter(exchange);
} else {
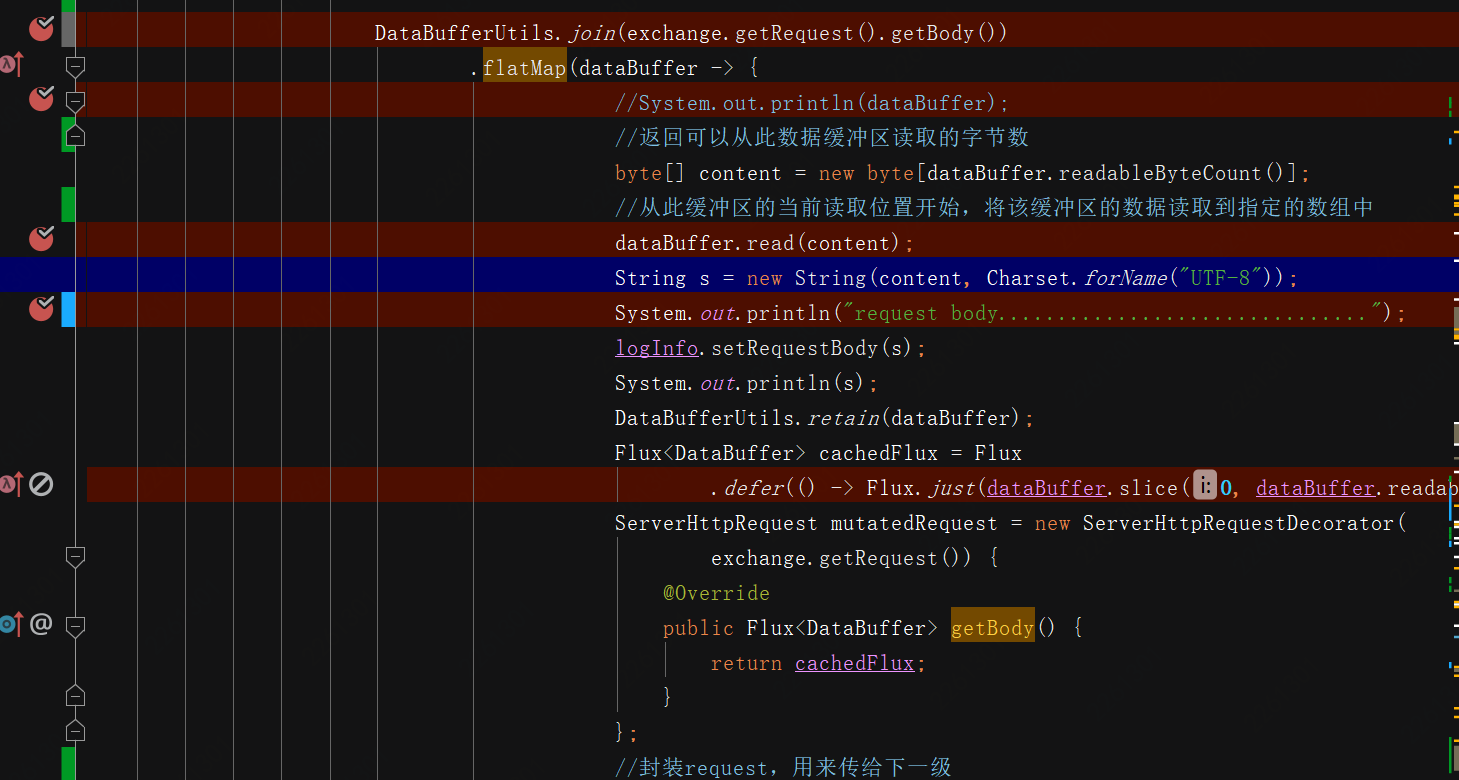
return DataBufferUtils.join(exchange.getRequest().getBody())
.flatMap(dataBuffer -> {
DataBufferUtils.retain(dataBuffer);
Flux<DataBuffer> cachedFlux = Flux
.defer(() -> Flux.just(dataBuffer.slice(0, dataBuffer.readableByteCount())));
ServerHttpRequest mutatedRequest = new ServerHttpRequestDecorator(
exchange.getRequest()) {
@Override
public Flux<DataBuffer> getBody() {
return cachedFlux;
}
};
// exchange.getAttributes().put(CACHE_REQUEST_BODY_OBJECT_KEY, cachedFlux);
return chain.filter(exchange.mutate().request(mutatedRequest).build());
});
}
}
@Override
public int getOrder() {
return Ordered.HIGHEST_PRECEDENCE;
}
}
CacheBodyGlobalFilter这个全局过滤器的目的就是把原有的request请求中的body内容读出来,并且使用ServerHttpRequestDecorator这个请求装饰器对request进行包装,重写getBody方法,并把包装后的请求放到过滤器链中传递下去。这样后面的过滤器中再使用exchange.getRequest().getBody()来获取body时,实际上就是调用的重载后的getBody方法,获取的最先已经缓存了的body数据。这样就能够实现body的多次读取了。
值得一提的是,这个过滤器的order设置的是Ordered.HIGHEST_PRECEDENCE,即最高优先级的过滤器。优先级设置这么高的原因是某些系统内置的过滤器可能也会去读body,这样就会导致我们自定义过滤器中获取body的时候报body只能读取一次这样的错误如下:
java.lang.IllegalStateException: Only one connection receive subscriber allowed.
at reactor.ipc.netty.channel.FluxReceive.startReceiver(FluxReceive.java:279)
at reactor.ipc.netty.channel.FluxReceive.lambda$subscribe$2(FluxReceive.java:129)
at
所以需要先解决body只能读取一次的问题,把CacheBodyGlobalFilter的优先级设到最高。
import io.netty.buffer.ByteBufAllocator;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.NettyDataBufferFactory;
import org.springframework.http.HttpMethod;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpRequestDecorator;
import org.springframework.stereotype.Component;
import org.springframework.util.MultiValueMap;
import org.springframework.web.server.ServerWebExchange;
import org.springframework.web.util.UriComponentsBuilder;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.net.URI;
import java.nio.charset.StandardCharsets;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
/**
* @author mjw
* @date 2020/3/24
*/
@Component
@Slf4j
public class AuthGlobalFilter implements GlobalFilter, Ordered
{
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain)
{
String bodyContent = RequestUtil.resolveBodyFromRequest(exchange.getRequest());
// TODO 身份认证相关逻辑
return chain.filter(exchange.mutate().build());
}
@Override
public int getOrder()
{
return -100;
}
}
这个类是自定义的身份认证的全局过滤器,这里需要说一下的就是读取body之后如何解析。由于spring cloud gateway使用的是webFlux,因此获取的body内容是Flux结构的,读取的方式如下:
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.core.io.buffer.DataBufferUtils;
import org.springframework.http.server.reactive.ServerHttpRequest;
import reactor.core.publisher.Flux;
import java.nio.charset.StandardCharsets;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author mjw
* @date 2020/3/30
*/
public class RequestUtil
{
/**
* 读取body内容
* @param serverHttpRequest
* @return
*/
public static String resolveBodyFromRequest(ServerHttpRequest serverHttpRequest){
//获取请求体
Flux<DataBuffer> body = serverHttpRequest.getBody();
StringBuilder sb = new StringBuilder();
body.subscribe(buffer -> {
byte[] bytes = new byte[buffer.readableByteCount()];
buffer.read(bytes);
// DataBufferUtils.release(buffer);
String bodyString = new String(bytes, StandardCharsets.UTF_8);
sb.append(bodyString);
});
return formatStr(sb.toString());
}
/**
* 去掉空格,换行和制表符
* @param str
* @return
*/
private static String formatStr(String str){
if (str != null && str.length() > 0) {
Pattern p = Pattern.compile("\\s*|\t|\r|\n");
Matcher m = p.matcher(str);
return m.replaceAll("");
}
return str;
}
}
实际上在网上查找资料的过程中发现,解析body内容网上普遍提到两种方式,一种就是上文中的方式,读取字节方式拼接字符串,另一种方式如下:
private String getBodyContent(ServerWebExchange exchange){
Flux<DataBuffer> body = exchange.getRequest().getBody();
AtomicReference<String> bodyRef = new AtomicReference<>();
// 缓存读取的request body信息
body.subscribe(dataBuffer -> {
CharBuffer charBuffer = StandardCharsets.UTF_8.decode(dataBuffer.asByteBuffer());
DataBufferUtils.release(dataBuffer);
bodyRef.set(charBuffer.toString());
});
//获取request body
return bodyRef.get();
}
但是网上有网友说这种方式最多能获取1024字节的数据,数据过长会被截断,导致数据丢失。这里笔者没有亲自验证过,只是把这种方式提供在这里供大家参考。
另外需要注意的是在我们创建ByteBuf对象后,它的引用计数是1,当你每次调用DataBufferUtils.release之后会释放引用计数对象时,它的引用计数减1,如果引用计数为0,这个引用计数对象会被释放(deallocate),并返回对象池。当尝试访问引用计数为0的引用计数对象会抛出IllegalReferenceCountException异常如下:
io.netty.util.IllegalReferenceCountException: refCnt: 0
at io.netty.buffer.AbstractByteBuf.ensureAccessible(AbstractByteBuf.java:1423) ~[netty-all-4.1.0.Final.jar:4.1.0.Final]
at io.netty.buffer.UnpooledHeapByteBuf.capacity(UnpooledHeapByteBuf.java:102) ~[netty-all-4.1.0.Final.jar:4.1.0.Final]
at io.netty.buffer.ReadOnlyByteBuf.capacity(ReadOnlyByteBuf.java:408) ~[netty-all-4.1.0.Final.jar:4.1.0.Final]
at io.netty.buffer.AbstractByteBuf.setIndex(AbstractByteBuf.java:126) ~[netty-all-4.1.0.Final.jar:4.1.0.Final]
at io.netty.buffer.ReadOnlyByteBuf.<init>(ReadOnlyByteBuf.java:50) ~[netty-all-4.1.0.Final.jar:4.1.0.Final]
at io.netty.buffer.ReadOnlyByteBuf.duplicate(ReadOnlyByteBuf.java:278) ~[netty-all-4.1.0.Final.jar:4.1.0.Final]
因此这里为了能够在多个自定义过滤器中使用相同的方法来获取body数据,就不进行release了。
参考文章
- https://blog.csdn.net/hong10086/article/details/92396319
- netty的异常分析 IllegalReferenceCountException refCnt: 0 - 残刃O的个人空间 - OSCHINA - 中文开源技术交流社区
- SpringCloud Gateway获取post请求体(request body)_51CTO博客_gateway 获取post请求的请求体
原文:那些年我们一起踩过的Spring Cloud Gateway获取body的那些坑 - 天马行空~_~ - 博客园
作者:天马行空~_~