MySQL总结
一. 事务
事务并发会导致各类问题,SQL 标准预定义了4种事务隔离级别,以满足不同程度的并发。每种隔离级别都能保证解决若干并发问题。
1. 事务的 ACID
| feature | 解释 |
|---|---|
| Atomic | 原子,要么一起完成要么都不做 |
| Consistency | 事务开始前和结束后数据都是满足约束规则的,如外键约束 |
| Isolation | 隔离性,并发事务之间不会互相影响,就像串行执行一样 |
| Duaration | 持久性,事务造成的修改是持久的,故障也不会丢失 |
2. 并发事务产生的问题
- 第一类丢失更新 (
回滚丢失)。在 A 进行期间,B 做了更新;A 如果回滚,B 的更新丢失。
所有隔离级别都不会发生这种现象
- 脏读(
Dirty Read):A 看到 B 进行中更新的数据,并以此为根据继续执行相关的操作;B 回滚,导致 A 操作的是脏数据。 - 不可重复读(
Non-repeatable Read):A 先查询一次数据,然后 B 更新之并提交,A 再次查询,得到和上一次不同的查询结果。 - 幻读(
Phantom Read):A 查询一批数据,B 插入或删除了某些记录并提交,A 再次查询,发现结果集中出现了上次没有的记录,或者上次有的记录消失了。 - 第二类丢失更新 (
覆盖丢失):A 和 B 查询同样的记录,进行 “读取、计算、更新”,即各自基于最初查询的结果(非必须) 更新记录并提交,后提交的数据将覆盖先提交的,导致最终数据错误。并发进行自增 / 自减是发生覆盖丢失的一个典型场景:
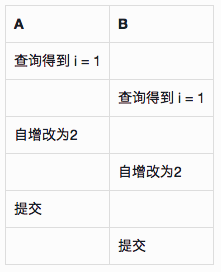
其中一个事务的更新被另外一个覆盖了,最终导致 i 错误。
3. 4个事务隔离级别
- read uncommited最弱,事务的所有动作对其他事务都是立即可见的。存在脏读、不可重复读、第二类丢失更新、幻读问题(全部并发问题都有)。
- read commited只能读到其他事务已提交的数据,中间状态的数据则看不到,解决了
脏读问题。 - repeatable read InnoDB的默认隔离级别。 解决了
不可重复读的问题,保证在一个事务内,对同一条记录的重复读都是一致的。依然存在幻读、第二类丢失更新问题。
InnoDB 在 Repeatable Read 隔离级别下提供了
phantom read的解决方案:引入
range lock区间锁,读/写时,除了对满足条件的记录加锁,记录之间的区间也加锁,保证不会出现区间内的插入操作。
- serial最高,所有事务都是串行的。啥并发问题都没有。
总结:
| . | 脏读 | 不可重复读 | 幻读 | 第二类丢失更新 |
|---|---|---|---|---|
| read uncommited | √ | √ | √ | √ |
| read commited | X |
√ | √ | √ |
| repeatable read | X |
X |
√ | √ |
| serial | X |
X |
X |
X |
二. 并发控制
数据库通常通过锁来实现上述隔离级别。MySQL能够根据设置的隔离级别自动管理事务内的锁,不需要开发人员关心,用户写的普通SQL语句就能获得上述并发保障。不过数据库也支持显式加锁,对于当前隔离级别无法解决的并发问题(对InnoDB的默认 RR 隔离级别而言,并发问题指的是 幻读 和 第二类丢失更新 ),通常有以下两种解决方式:
- 悲观锁 :在数据库事务中显式加锁。这种方法的逻辑是,假定每次访问资源都会出现冲突,每次均以排他形式访问数据库记录,因此称为 悲观锁 。在并发程度低的时候加的锁可能是不必要的,会浪费资源降低性能。
- 乐观锁 :在应用程序中使用版本控制手段进行冲突检测。这种方法认为DB的并发度较低,冲突不激烈,假定每次访问数据库都不会发生冲突,不显式加数据库锁,只在更新记录时由应用程序(通常是ORM框架)从DB取最新数据,并与当前提交的数据进行版本比对(通常用额外的一个Version字段,递增记录数据版本),从而判断是否出现了并发问题,因此称为 乐观锁 。 乐观锁只能解决第二类丢失更新(
覆盖丢失)问题 ,并发度低时,乐观锁能避免数据库级不必要的加锁,降低了开销。
InnoDB 在锁的基础上还搭配了 MVCC 作为优化,实现以上事务隔离级别。
1. 锁
two-phase locking protocol :事务内部只加锁不释放,在提交时一起释放
锁优化1:拆分,读写锁
读锁 – 共享锁 – shared
写锁 – 排他锁 – exclusive
工作方式和 JUC 里的读写锁一样。
锁优化2:降低粒度,表锁 & 行锁
表锁由 mysql服务器 实现,行锁由 存储引擎 实现。表锁行锁又细分成读写锁。
表锁
显式的表锁:
lock table xxx read/write;
MyISAM几乎完全依赖MySQL服务器提供的表锁机制,查询自动加S表锁,更新自动加X表锁。
使用MyISAM时注意对表锁的优化:
- 缩短锁定时间:拆分query / 索引
- 打开concurrent insert(在尾部并发insert)
- 0 关闭尾部并发insert
- 1 如果MyISAM表中没有空洞(即表的中间没有被删除的行),MyISAM允许在一个事务读表的同时,另一个事务从表尾插入记录。这也是MySQL的默认设置。
- 2 无论MyISAM表中有没有空洞,都允许在表尾并发插入记录
- 根据需要设置读写的优先级。默认写大于读
行锁
InnoDB实现了行锁,基于索引的 index-row locking, 如果锁了次级索引中的记录,则对应主索引中的记录也会被锁住 。
update/delete/insert 动作会自动加x锁。
查询时也可以设置显式加锁:
select... lock in shared mode: s lockselect... for update: x lock
查询锁的争用情况
- 表锁
show status like 'table%'
Table_locks_immediate:立即获得表锁的次数
Table_locks_waited:需要等待获得表锁的次数 - innodb的行锁
show status like 'innodb_row_lock'
current_waits:
waits:
time:
time_avg:
time_max:
2. MVCC
InnoDB 并不仅仅使用上述的锁机制控制并发,它还搭配了另外一种用于提高并发度的被称为 “Multi-Version Concurrency Control 多版本并发控制” 机制一起使用。简单的说,MVCC为某条记录创建多个snapshot,不同事务读取各自的snapshot,互不影响。MVCC是对锁机制的一种优化,普通的select不加锁, read commited MVCC读, repeatable read MVCC读保证了可重复读、避免幻读。MVCC只对select有效,对加锁的select、update、delete无效。
MVCC 只工作在RC & RR两个隔离级别下,Read uncommited 隔离级别不支持 MVCC,在这个级别下每次都是读取最新版本的数据行;Serializable 也不支持 MVCC,该级别下每个 read 动作都会为记录加上读锁。
MySQL的两种read方式
在MVCC并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
snapshot read(non-lock) / consistent readcurrent read(lock) / lock read
a. “snapshot read”
普通的select就是snapshot read,读 MVCC 的快照,不加锁, 但是不同的隔离级别中的行为是不一样的:
- RC: 最近的snapshot – 可看到其他事务已提交的内容
- RR: 事务开始时的snapshot – 可重复读、避免幻读
可以看到,snapshot read 在RC和RR中的工作方式都满足其隔离级别的定义。
If the transaction isolation level is REPEATABLE READ (the default level), all consistent reads within the same transaction read the snapshot established by the first such read in that transaction.
You can get a fresher snapshot for your queries by committing the current transaction and after that issuing new queries.
With READ COMMITTED isolation level, each consistent read within a transaction sets and reads its own fresh snapshot.
b. “current read / lock read”
lock read 操作的是数据的最新版本,且对记录加锁。以下动作属于 lock read:
select... lock in shared mode: s lockselect... for update: x lock- DML(insert/delete/update)也属于
lock read
SELECT … FOR UPDATE and SELECT … LOCK IN SHARE MODE Locking Reads
在 在RR隔离级别上 ,lock read 除了会加记录锁,还会为记录之间的间隙加上 gap lock ,从而解决 phantom read 问题。
3. gap lock & phantom read
在 repeatable read 级别上, lock read 时使用了 gap-key lock 解决 phathom read 问题: 不仅锁找到的记录,还锁区间,保证区间内的值无法被插入。 read committed 只有记录锁,存在幻读。
注意,无法使用索引时会走主索引实现全表扫描,此时会给所有的记录加上record lock,并对其所有的区间加gap lock,表完全锁死,此时只能进行 snapshot read,极大地降低并发,这就是为何update/delete尽量要走索引的原因。
何登成的《MySQL 加锁处理分析》
innodb-record-level-locks`
MySQL/InnoDB定义的4种隔离级别:
Read Uncommited
可以读取未提交记录。此隔离级别,不会使用,忽略。Read Committed (RC)
快照读忽略,本文不考虑。针对当前读,RC隔离级别保证对读取到的记录加锁 (记录锁),存在幻读现象。
Repeatable Read (RR)
快照读忽略,本文不考虑。针对当前读,RR隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象。
Serializable
从MVCC并发控制退化为基于锁的并发控制。不区别快照读与当前读,所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。Serializable隔离级别下,读写冲突,因此并发度急剧下降,在MySQL/InnoDB下不建议使用。
三. 优化query (粗略)
定位瓶颈
IO or CPU?
工具
- explain & profile
基本原则
- join时小结果集驱动大结果集
- 利用索引完成排序/分组
- 只取需要的列(?)
a. network
b. 不能使用Covering index
c. 优化排序 - 仅仅使用最有效的过滤条件
建立索引的字段越小越好,减少IO - 避免复杂join和子查询
对于MyISAM,join会锁住所有相关的表(s lock),可能阻塞DML其他很长时间,此时可以在程序中做join,降低对锁的占用,减少阻塞;
对应用而言,SQL的执行时间:网络/执行(CPU+IO)/锁阻塞,优化瓶颈
子查询实现不好,不一定会走索引
Explain
四. 索引
Practical MySQL indexing guidelines
MyISAM 和 InnoDB 的索引,采用的数据结构都是B+树。
1. B树和B+树
B树
B树的结构类似二叉查找树,只不过节点的度远远大于2,查找的复杂度为树的高度,O(logdN):
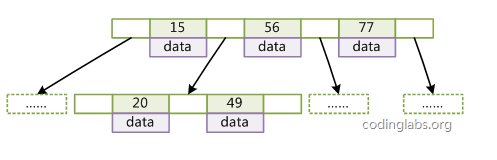
通常会将根据硬盘上一个page的大小来调整节点的度,原因是:
- 基于外存的查找数据结构中,性能的瓶颈在于IO,这样的处理一可以让一个节点只需要一次IO
- 二可以显著降低树的高度,查找时只需几次page的IO即可定位到目标。
B+树
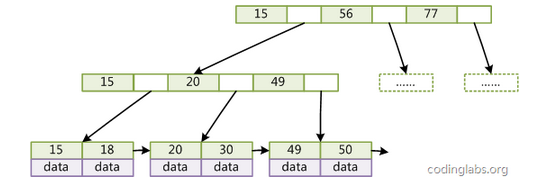
B+树是对B树的优化:
- 只有叶子节点存data,内节点只存key;
好处: ** 提高内节点的度,降低高度 ** - 叶子节点加上了next指针,形成一个链表
好处: ** 快速范围查找,只需确定起点和终点,顺序扫描即可 **
2. MyISAM的索引
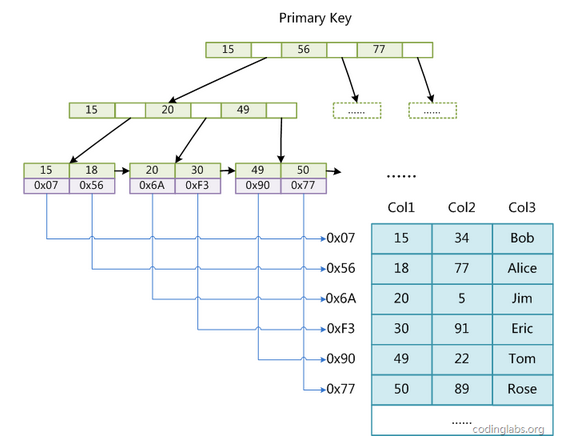
索引和数据分离,数据文件:堆表(按插入有序)
主键索引和非主键索引结构一致,叶子节点存储的是行的物理位置信息(row number)
3. InnoDB的索引
primary index(主键索引)
数据文件就是主键索引文件,叶子节点存真实数据,这种方式称为 聚集索引 。
如果没有主键,InnoDB会试着使用一个Unique Nonnullable index代替;如果没有这种索引,会定义隐藏的主键。
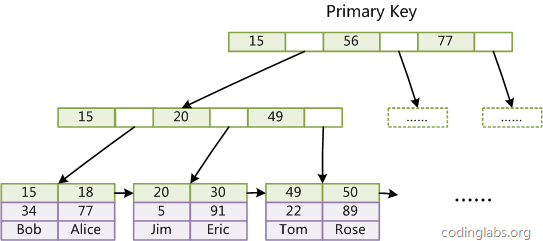
secondary index
非主键上的索引称为次级索引,叶子节点存 主键 ,此时需要查找两次。
优缺点
优点: 将相关数据保存在一起,减少IO;MyISAM访问每个行都得访问数据文件
缺点:
- B+树的节点按page聚集,存储着数据,因此主索引叶子节点分裂的机会远远大于非聚集索引;split会导致
- 移动大量数据;
- 需要更多空间(碎片);
- split时会给整个索引加x锁,不可访问
- 按主键顺序插入最快,因为记录被顺序插到索引的最末,节点 split 的开销很小;乱序插入慢,因为新记录很大机会被插入到已满的叶子节点,引起频繁分裂,因此 InnoDB 更适合用自增主键 ;
- secondary index包含了主键,体积可能很大,因此 不适合用过长字段当主键 ;
- 在secondary index上可能需要查找两次,一次查自己,一次查主索引。
4. 什么样的查询条件会走索引?
区分
范围查询和等值查询
in是多个等值查询,between二者都有可能。范围查询 使用索引的方式,是先确定起点,再根据叶子节点组成的链表顺序扫描,直到终点。
等值查询 则是从上到下搜索树。
假如有索引 <a,b,c,d> :
a) 最左前缀的等值查询
一旦出现空洞,后面的列就不能使用索引了,但空洞可以用 in所有值 填充
b) 范围查询
只有第一个出现的范围查询及其前面的列(前提是要构成最左前缀)可以使用索引,后面的即使构成最左前缀也不会走索引。
因此,较常进行范围查询的列要放在索引的后面。
c) 字符串 % 如果放在开头则无法走索引
5. 建立索引时的优化
a) 不适合创建索引的情况
- 唯一性太差的列
引擎根据统计信息会做优化,可能建了也不走 - 频繁更新的列
需要同时维护索引和数据
b) 前缀索引 和 selectivity(选择性)
问题:列太长,太消耗空间;解决方案:用前缀建立索引
但是又要保证良好的selectivity
selectivity = (distinct values) / all records
c) 尽量使用多列复合索引而不是多个单列索引
减少维护索引的开销
多个单列索引老版本只会选一个,5.0以后可以用index merge,扫描多个再合并结果(or/and)
d) 选择正确的列顺序
- 一般来说选择性高的放前面,在最初阶段就可以排除大部分记录,减少后续需要考察的数据量;
- 最常用的放在前面,范围查询的字段尽量靠后。
6. 查询优化
a) 查询条件中不要对列做运算,否则无法使用索引;
b) 使用“覆盖索引”技巧
Covering index: 覆盖了查询的所有列,避免访问数据文件/聚集索引
发起的查询被索引覆盖时,会在Extra出现Using Index
c) 优化join
MySQL只支持nested loop join,没有hash join或者sort merge join。
数据库 join 类型:
nested-loop join
两层循环,分驱动表(外层,小)和被驱动表(内层)。MySQL 只有这种 join 方式。sort-merge join
两边都先 sort(有索引就不用了),用两个指针指向两边的第一个元素,依次找相同值。
和 nested-loop join 类似,但利用了排序的性质,内层循环从上次停止的地方开始就可以,不要从头开始找起。hash join
一边构造一个哈希表(或布隆过滤器),另一边依次判断记录是否在其中
当join无法使用索引(type是all/index/range/index_merge,用到是ref)时会用到join buffer,缓存中间的结果集
优化:
- 某些情况下拆分join效率更高:
- 在应用端可以利用缓存
- 减少MyISAM的表锁时间
- 对大表用in替换join,更高效
- 减小最外层循环次数,即用小结果集驱动join(优化器会帮你挑选较小的表做驱动表)
- 保证被驱动表上的join字段被索引
- 只 group by 或 order by 驱动表上的列,这样可以在 join 前排序
- 被驱动表无法走索引时,保证join buffer足够大
d) 优化 order by
当不能用索引实现排序时,mysql必须对存储引擎返回的记录排序,这个过程被称为filesort(但不一定发生在磁盘上)。纯内存时快速排序,外存时分块快速排序再归并。
两种filesort算法:
- order by 字段和行指针取出,在sort buffer中排序;然后通过行指针取出需要的列。需要访问两次数据,但内存消耗少。
- 一次性将所有需要的列取出,在sort buffer中排序,需要更多内存。
参数:max_length_for_sort_data,结果集长度超过该参数时用第一种。
对join的排序:
- 如果只用了驱动表的字段排序:先排序,再join
- 否则先join,结果集放temp table,然后再排序(Using temporary; Using filesort)
优化:
- 尽量走索引
- order by时必须要能使用索引的最左前缀(order by+where条件中的常量组成最左前缀也可以),且order by的方向都相同
- join时,order by的列如果引用第一个表(驱动表),可以在 join 前先排好序
- 优化filesort
- 内存多时加大max_length_for_sort_data,返回记录小于时用新算法,大于用老算法;
- 用第二种算法时,去掉不必要的返回字段(会用更多内存)
- 加大sort_buffer_size,减小排序过程的IO
e) 优化 group by / distinct
group by:
比order by多了分组和聚合函数计算的步骤,因此优化方式和order by基本类似。
1. 走索引,可以避免额外排序
索引访问方式
1.
loose index scan(MySQL不支持)当前对 范围查询 的处理方式(range scan)是
走叶子节点链表扫描,当后续有其他列上的过滤条件时,不支持在 从上往下搜索的时候,对一个范围内的所有子树,利用后续列的其他条件进行查找并合并结果集 的工作方式。举个例子,idx(a,b,c),where a = 1 and b < 3 and c = 1,不用loose index scan时的range scan方式:
首先定位到 a=1 的节点,然后在这个子树中搜索 b=3 的最右侧叶子节点,接着往前扫描,并用 c=1 在链表上过滤,这种方式在搜索的时候实际上只用到了ab两列;
但是显然有一种更好的方式,即在树上从上往下搜索到b<3的所有区间后,对每个子树用c=1的条件去扫描,并合并结果。这就是所谓的loose index scan。
这就是 idx(a,b,c)少了只有a/c当查询条件是只能用到a列;ab都有范围查询只能用到a列 的根本原因。
Mysql的B+索引只支持等值查询, in实际上是和其他条件进行笛卡尔积后的多个等值查询 ,因此在查询b/c列时,如果用a in (‘男’,’女’)补上这个空洞时,又是可以走索引的。
可以使用下面两种方式加速分组 :
2.
伪loose index scan:group by在有些情况下可以使用这种方式加速查询。
idx(a,b,c),
select max(c) where ... group by a,b时对每个 a 及 b 的组合,从该节点出发找到该子树的最左(右)节点,就能知道这个 group 中 c 的最大值了;最后合并结果即可。这种工作方式和真正的 loose scan 类似,都是合并子树的搜索结果,而且仅需扫描子树的部分节点。它的局限在于仅适用某些聚合函数如min/max,且查询字段必须在 group by 字段后面,二者一起组成最左前缀。
3.
Tight index scan:其实就是利用索引的有序性,工作方式和
伪loose index scan类似,但需要扫描满足条件的组合所对应子树中的所有节点,再进行分组/聚合,而不能直接拿到结果。
2. 不能用索引时,mysql必须先将数据放入临时表,然后filesort。
distinct:
与group by的实现方式是一样的,因此优化方式也类似:
伪loose index scantight index scanfilesort,但distinct不需要排序
f) count
注意区分以下两种 count :
count(*)
统计结果集的行count(列/表达式)
统计值的个数,排除null
MyISAM维护了表的总行数,所以没有where条件的 count(*) 很快。
工作方式:扫描符合条件的记录,统计。
一个sql语句统计不同值的count:
SELECT COUNT(color = 'blue' OR NULL) AS blue, COUNT(color = 'red' OR NULL) AS red FROM items
优化
用 “covering index” 技巧让 count 利用索引就能完成,不要访问数据文件。
g) limit & offset
一般瓶颈在于扫描的数据太多,limit 10000,20会扫描10020行数据,再丢弃前10000行.
优化:利用covering index在索引上偏移,而不是全表上偏移 – 可以先在索引上偏移再join原表获取其他列。
(没别的办法了??)
h) union
MySQL总是用temp table实现union
使用 union all 而不是 union ,后者会对temp table做distinct操作,开销很大
** 附:数据访问方式,出现在explain的type列里 **
- (all) Full table scan 全表扫描
- (index) Index scan 索引全部扫描:找到最左叶子节点,然后走链表
- (range) Range Scan 索引范围扫描:找到范围的最左(右)侧叶子,然后走链表
例外:in显示的是range,但是是索引唯一扫描,等同于多个相等条件 - (ref/eq_ref) Unique Index Lookup 索引唯一扫描,走树
- (const) Constant
五. 可扩展设计
分布式事务
- 合理设计切分规则,保证事务所需数据在同一个DB上,避免分布式事务
- 拆分成小事务,app保证整体事务完整性
最终一致性
为了HA/负载均衡需要冗余数据,数据冗余的地方就存在一致性的问题
同一个数据只要保存在多个地方,且至少有一个地方被写,就存在一致性问题
如果保存在多个地方被写,情况就更复杂了,涉及到数据的传播/并发/事务,尽量避免这个情况,保证数据在一个地方被增删改。
shard还是一个数据在一个地方
如果session是各个容器自己管理的,因为要是强一致性的,必然需要session的复制
如果每个容器有自己的本地cache,且会update/remove,和cpu的L1/L2/L3缓存的情形类似,都要实现cache的传播
Replication
- Master-Slaves 读写分离,负载均衡
- Dual Master 双机热备HA
数据切分(shard)
垂直
按业务模块切分
需要程序进行不同库之间的join
水平
每个库的表结构是一样的,按id划分数据
数据局部性好,很多表关联/事务能够在一个DB完成
结合:先垂直再水平
切分后的整合
统一数据访问层 – 路由规则/解析sql/合并结果/join/分布式事务/负载均衡都可以在这一层搞定
一些开源产品:
- MySQL Proxy
-
Amoeba (JDBC以下)
query路由/过滤,负载均衡,读写分离,HA
主要解决: -
数据切分后复杂数据源整合;
-
提供数据切分规则并降低数据切分规则给数据库带来的影响;
-
降低数据库与客户端的连接数;
-
读写分离路由
Amoeba for MySQL/Aladin
- hibernate shards / ibatis shards
问题:
- 分布式事务
- 跨节点join
- 跨节点合并排序分页
都由应用解决吧
参考书籍:
- 《高性能MySQL》
- 张宴的《MySQL调优与架构设计》