一、分布式系统中ID生成器要求
1.1 全局唯一性
不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
1.2 递增
比较低要求的条件为趋势递增,即保证下一个ID一定大于上一个ID,而比较苛刻的要求是连续递增,如1,2,3等等。
1.3 高可用高性能
ID生成事关重大,一旦挂掉系统崩溃;高性能是指必须要在压测下表现良好,如果达不到要求则在高并发环境下依然会导致系统瘫痪。
1.4 信息安全
如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
第二条和第四条有点冲突,需要结合具体的业务场景。
二、常见企业级解决方案(除雪花算法)
2.1 UUID
优点:
能够保证独立性,程序可以在不同的数据库间迁移,效果不受影响。
保证生成的ID不仅是表独立的,而且是库独立的,这点在你想切分数据库的时候尤为重要。
缺点:
性能为题:UUID太长,通常以36长度的字符串表示,对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能
UUID无业务含义:很多需要ID能标识业务含义的地方不使用
不满足递增要求
信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
2.2 基于数据库方案
利用数据库生成ID是最常见的方案。能够确保ID全数据库唯一。其优缺点如下:
优点:
非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。
有单点故障的风险。在性能达不到要求的情况下,比较难于扩展。
如果涉及多个系统需要合并或者数据迁移会比较麻烦。
分表分库的时候会有麻烦。
三、雪花算法
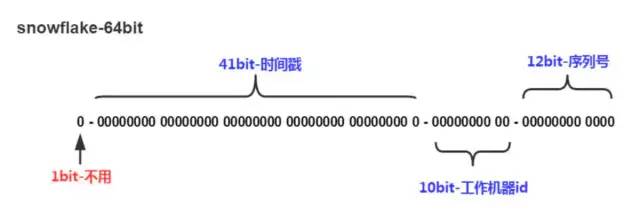
3.1 说明
41位为时间戳,12位为在这一刻能够产生2^12个自增的Id这结合了自增Id的优势,同时10位机器ID(dataCenterId 5位和machineId 5位)确保了分布式能够支持1024台节点。
Twitter的分布式雪花算法 SnowFlake 每秒自增生成26个万可排序的ID
1、twitter的SnowFlake生成ID能够按照时间有序生成
2、SnowFlake算法生成id的结果是一个64bit大小的整数
3、分布式系统内不会产生重复id(用有datacenterId和machineId来做区分)
datacenterId(分布式)(服务ID 1,2,3…) 每个服务中写死
machineId(用于集群) 机器ID 读取机器的环境变量MACHINEID 部署时每台服务器ID不一样。
3.2 缺点:
强依赖时钟,如果主机时间回拨,则会造成重复ID