解决SpringBoot中多字段联合逻辑校验问题
前言
本以为洋洋洒洒的把 Java/Spring 数据(绑定)校验这块说了这么多,基本已经算完结了。但今天中午一位热心小伙伴在使用 Bean Validation 做数据校验时上遇到了一个稍显特殊的case,由于此校验场景也比较常见,因此便有了本文对数据校验补充。
关于 Java/Spring 中的数据校验,我有理由坚信你肯定遇到过这样的场景需求:在对 JavaBean 进行校验时, b属性的校验逻辑是依赖于a属性的值的 ;换个具象的例子说:当且仅当属性a的值=xxx时,属性b的校验逻辑才生效。这也就是我们常说的多字段联合校验逻辑~因为这个校验的case比较常见,因此促使了我记录本文的动力,因为它会变得有意义和有价值。当然对此问题有的小伙伴说可以自己用 if else 来处理呀,也不是很麻烦。本文的目的还是希望对数据校验一以贯之的做到更清爽、更优雅、更好扩展而努力。
需要有一点坚持:既然用了
Bean Validation去简化校验,那就(最好)不要用得四不像,遇到问题就解决问题~
热心网友问题描述
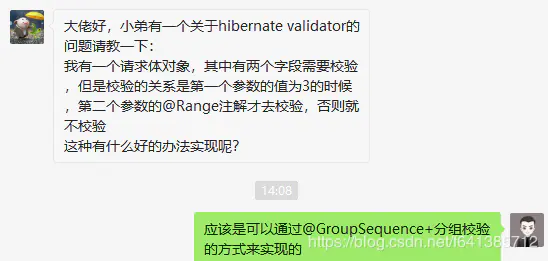
JavaBean如下:
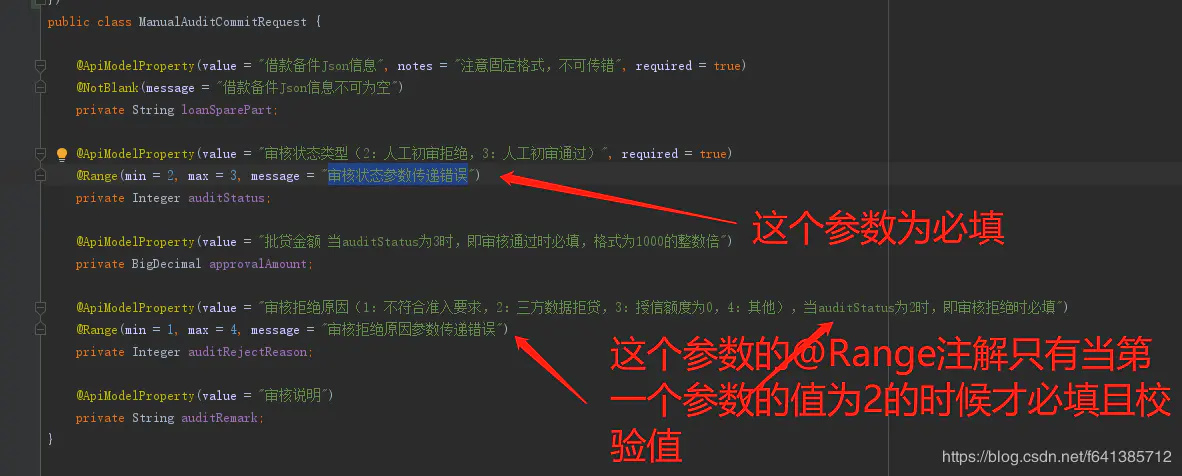
校验需求描述简述如下:
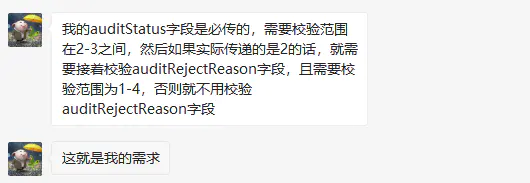
这位网友描述的真实生产场景问题,这也是本文讲解的内容所在。虽然这是在
Spring MVC 条件的下使用的数据校验,但按照我的习惯为了 更方便 的说明问题,我会把此部分功能单摘出来,说清楚了方案和原理,再去实施解决问题本身(文末)~
方案和原理
对于单字段的校验、级联属性校验等,通过阅读我的系列文章,我有理由相信小伙伴们都能 驾轻就熟 了的。本文给出一个最简单的例子简单"复习"一下:
@Getter
@Setter
@ToString
public class Person {
@NotNull
private String name;
@NotNull
@Range(min = 10, max = 40)
private Integer age;
@NotNull
@Size(min = 3, max = 5)
private List<String> hobbies;
// 级联校验
@Valid
@NotNull
private Child child;
}
测试:
public static void main(String[] args) {
Person person = new Person();
person.setName("fsx");
person.setAge(5);
person.setHobbies(Arrays.asList("足球","篮球"));
person.setChild(new Child());
Set<ConstraintViolation<Person>> result = Validation.buildDefaultValidatorFactory().getValidator().validate(person);
// 对结果进行遍历输出
result.stream().map(v -> v.getPropertyPath() + " " + v.getMessage() + ": " + v.getInvalidValue()).forEach(System.out::println);
}
运行,打印输出:
child.name 不能为null: null
age 需要在10和40之间: 5
hobbies 个数必须在3和5之间: [足球,篮球]
结果符合预期,(级联)校验生效。
通过使用
@Valid可以实现递归验证,因此可以标注在List上,对它里面的每个对象都执行校验
问题来了,针对上例,现在我有如下需求:
- 若20 <= age < 30,那么
hobbies的size需介于1和2之间 - 若30 <= age < 40,那么
hobbies的size需介于3和5之间 - age其余值,
hobbies无校验逻辑
实现方案
Hibernate Validator 提供了 非标准 的 @GroupSequenceProvider 注解。本功能提供根据当前对象实例的状态, 动态来决定 加载那些校验组进入默认校验组。
为了实现上面的需求达到目的,我们需要借助 Hibernate Validation 提供给我们的 DefaultGroupSequenceProvider 接口来处理。
// 该接口定义了:动态Group序列的协定
// 要想它生效,需要在T上标注@GroupSequenceProvider注解并且指定此类为处理类
// 如果`Default`组对T进行验证,则实际验证的实例将传递给此类以确定默认组序列(这句话特别重要 下面用例子解释)
public interface DefaultGroupSequenceProvider<T> {
// 合格方法是给T返回默认的组(多个)。因为默认的组是Default嘛~~~通过它可以自定指定
// 入参T object允许在验证值状态的函数中动态组合默认组序列。(非常强大)
// object是待校验的Bean。它可以为null哦~(Validator#validateValue的时候可以为null)
// 返回值表示默认组序列的List。它的效果同@GroupSequence定义组序列,尤其是列表List必须包含类型T
List<Class<?>> getValidationGroups(T object);
}
注意:
- 此接口Hibernate并没有提供实现
- 若你实现请必须提供一个空的构造函数以及保证是线程安全的
按步骤解决多字段组合验证的逻辑: 1、自己实现 DefaultGroupSequenceProvider 接口(处理Person这个Bean)
public class PersonGroupSequenceProvider implements DefaultGroupSequenceProvider<Person> {
@Override
public List<Class<?>> getValidationGroups(Person bean) {
List<Class<?>> defaultGroupSequence = new ArrayList<>();
defaultGroupSequence.add(Person.class); // 这一步不能省,否则Default分组都不会执行了,会抛错的
if (bean != null) { // 这块判空请务必要做
Integer age = bean.getAge();
System.err.println("年龄为:" + age + ",执行对应校验逻辑");
if (age >= 20 && age < 30) {
defaultGroupSequence.add(Person.WhenAge20And30Group.class);
} else if (age >= 30 && age < 40) {
defaultGroupSequence.add(Person.WhenAge30And40Group.class);
}
}
return defaultGroupSequence;
}
}
2、在待校验的javaBean里使用 @GroupSequenceProvider 注解指定处理器。并且定义好对应的校验逻辑(包括分组)
@GroupSequenceProvider(PersonGroupSequenceProvider.class)
@Getter
@Setter
@ToString
public class Person {
@NotNull
private String name;
@NotNull
@Range(min = 10, max = 40)
private Integer age;
@NotNull(groups = {WhenAge20And30Group.class, WhenAge30And40Group.class})
@Size(min = 1, max = 2, groups = WhenAge20And30Group.class)
@Size(min = 3, max = 5, groups = WhenAge30And40Group.class)
private List<String> hobbies;
/**
* 定义专属的业务逻辑分组
*/
public interface WhenAge20And30Group {
}
public interface WhenAge30And40Group {
}
}
测试用例同上,做出简单修改: person.setAge(25) ,运行打印输出:
年龄为:25,执行对应校验逻辑
年龄为:25,执行对应校验逻辑
没有校验失败的消息(就是好消息),符合预期。再修改为 person.setAge(35) ,再次运行打印如下:
年龄为:35,执行对应校验逻辑
年龄为:35,执行对应校验逻辑
hobbies 个数必须在3和5之间: [足球, 篮球]
校验成功,结果符合预期。 从此案例可以看到,通过 @GroupSequenceProvider 我完全实现了多字段组合校验的逻辑,并且代码也非常的优雅、可扩展,希望此示例对你有所帮助。
本利中的provider处理器是Person专用的,当然你可以使用 Object+反射 让它变得更为通用,但本着职责单一原则,我并不建议这么去做。
使用JSR提供的 @GroupSequence 注解控制校验顺序
上面的实现方式是最佳实践,使用起来不难,灵活度也非常高。但是我们 必须要明白 它是 Hibernate Validation 提供的能力,而不费 JSR 标准提供的。 @GroupSequence 它是 JSR 标准提供的注解(只是没有provider强大而已,但也有很适合它的使用场景)
// Defines group sequence. 定义组序列(序列:顺序执行的)
@Target({ TYPE })
@Retention(RUNTIME)
@Documented
public @interface GroupSequence {
Class<?>[] value();
}
顾名思义,它表示 Group组序列 。 默认情况下,不同组别的约束验证是无序的 在某些情况下,约束验证的 顺序 是非常的重要的,比如如下两个场景:
- 第二个 组 的约束验证依赖于第一个约束执行完成的结果(必须第一个约束正确了,第二个约束执行才有意义)
- 某个Group组的校验非常耗时,并且会消耗比较大的CPU/内存。那么我们的做法应该是把这种校验 放到最后 ,所以对顺序提出了要求
一个组可以定义为其他组的序列 ,使用它进行验证的时候必须符合该序列规定的顺序。 在使用组序列验证的时候 , 如果序列前边的组验证失败 ,则后面的组将不再给予验证。
给个栗子:
public class User {
@NotEmpty(message = "firstname may be empty")
private String firstname;
@NotEmpty(message = "middlename may be empty", groups = Default.class)
private String middlename;
@NotEmpty(message = "lastname may be empty", groups = GroupA.class)
private String lastname;
@NotEmpty(message = "country may be empty", groups = GroupB.class)
private String country;
public interface GroupA {
}
public interface GroupB {
}
// 组序列
@GroupSequence({Default.class, GroupA.class, GroupB.class})
public interface Group {
}
}
测试:
public static void main(String[] args) {
User user = new User();
// 此处指定了校验组是:User.Group.class
Set<ConstraintViolation<User>> result = Validation.buildDefaultValidatorFactory().getValidator().validate(user, User.Group.class);
// 对结果进行遍历输出
result.stream().map(v -> v.getPropertyPath() + " " + v.getMessage() + ": " + v.getInvalidValue()).forEach(System.out::println);
}
运行,控制台打印:
middlename middlename may be empty: null
firstname firstname may be empty: null
现象:只有 Default 这个Group的校验了,序列上其它组并没有执行校验。更改如下:
User user = new User();
user.setFirstname("f");
user.setMiddlename("s");
运行,控制台打印
lastname lastname may be empty: null
现象: Default 组都校验通过后,执行了GroupA组的校验。但GroupA组校验木有通过,GroupB组的校验也就不执行了~ @GroupSequence 提供的组序列顺序执行以及 短路 能力,在很多场景下是非常非常好用的。
针对本例的多字段组合逻辑校验,若想借助 @GroupSequence 来完成,相对来说还是比较困难的。但是也并不是不能做,此处我提供参考思路:
- 多字段之间的逻辑、“通信”通过类级别的自定义校验注解来实现(至于为何必须是类级别的,不用解释吧~)
@GroupSequence用来控制组执行顺序(让类级别的自定义注解先执行)- 增加Bean级别的第三属性来辅助校验~
当然喽,在实际应用中不可能使用它来解决如题的问题,所以我此处就不费篇幅了。我个人建议有兴趣者可以自己动手试试,有助于加深你对数据校验这块的理解。
这篇文章里有说过:数据校验注解是可以标注在Field属性、方法、构造器以及 Class 类级别上的。那么关于它们的校验顺序,我们是可控的,并不是网上有些文章所说的无法抉择~
说明:顺序只能控制在分组级别,无法控制在约束注解级别。因为一个类内的约束(同一分组内),它的顺序是
Set> metaConstraints来保证的,所以可以认为同一分组内的校验器是木有执行的先后顺序的(不管是类、属性、方法、构造器…)
所以网上有说:校验顺序是先校验字段属性,在进行类级别校验不实,请注意辨别。
原理解析
本文中,我借助 @GroupSequenceProvider 来解决了平时开发中多字段组合逻辑校验的痛点问题,总的来说还是使用简单,并且代码也够模块化,易于维护的。 但对于上例的结果输出,你可能和我一样至少有如下疑问:
- 为何必须有这一句:
defaultGroupSequence.add(Person.class) - 为何
if (bean != null)必须判空 - 为何
年龄为:35,执行对应校验逻辑被输出了两次(在判空里面还出现了两次哦~),但校验的失败信息却只有符合预期的一次
带着问题,我从 validate 校验的执行流程上开始分析: 1、入口: ValidatorImpl.validate(T object, Class... groups)
ValidatorImpl:
@Override
public final <T> Set<ConstraintViolation<T>> validate(T object, Class<?>... groups) {
Class<T> rootBeanClass = (Class<T>) object.getClass();
// 获取BeanMetaData,类上的各种信息:包括类上的Group序列、针对此类的默认分组List们等等
BeanMetaData<T> rootBeanMetaData = beanMetaDataManager.getBeanMetaData( rootBeanClass );
...
}
2、 beanMetaDataManager.getBeanMetaData(rootBeanClass) 得到待校验Bean的元信息
请注意,此处只传入了Class,并没有传入Object。这是为啥要加
!= null判空的核心原因(后面你可以看到传入的是null)。
BeanMetaDataManager:
public <T> BeanMetaData<T> getBeanMetaData(Class<T> beanClass) {
...
// 会调用AnnotationMetaDataProvider来解析约束注解元数据信息(当然还有基于xml/Programmatic的,本文略)
// 注意:它会递归处理父类、父接口等拿到所有类的元数据
// BeanMetaDataImpl.build()方法,会new BeanMetaDataImpl(...) 这个构造函数里面做了N多事
// 其中就有和我本例有关的defaultGroupSequenceProvider
beanMetaData = createBeanMetaData( beanClass );
}
3、 new BeanMetaDataImpl( ... ) 构建出此Class的元数据信息(本例为 Person.class )
BeanMetaDataImpl:
public BeanMetaDataImpl(Class<T> beanClass,
List<Class<?>> defaultGroupSequence, // 如果没有配置,此时候defaultGroupSequence一般都为null
DefaultGroupSequenceProvider<? super T> defaultGroupSequenceProvider, // 我们自定义的处理此Bean的provider
Set<ConstraintMetaData> constraintMetaDataSet, // 包含父类的所有属性、构造器、方法等等。在此处会分类:按照属性、方法等分类处理
ValidationOrderGenerator validationOrderGenerator) {
... //对constraintMetaDataSet进行分类
// 这个方法就是筛选出了:所有的约束注解(比如6个约束注解,此处长度就是6 当然包括了字段、方法等上的各种。。。)
this.directMetaConstraints = getDirectConstraints();
// 因为我们Person类有defaultGroupSequenceProvider,所以此处返回true
// 除了定义在类上外,还可以定义全局的:给本类List<Class<?>> defaultGroupSequence此字段赋值
boolean defaultGroupSequenceIsRedefined = defaultGroupSequenceIsRedefined();
// 这是为何我们要判空的核心:看看它传的啥:null。所以不判空的就NPE了。这是第一次调用defaultGroupSequenceProvider.getValidationGroups()方法
List<Class<?>> resolvedDefaultGroupSequence = getDefaultGroupSequence( null );
... // 上面拿到resolvedDefaultGroupSequence 分组信息后,会放到所有的校验器里去(包括属性、方法、构造器、类等等)
// so,默认组序列还是灰常重要的(注意:默认组可以有多个哦~~~)
}
@Override
public List<Class<?>> getDefaultGroupSequence(T beanState) {
if (hasDefaultGroupSequenceProvider()) {
// so,getValidationGroups方法里请记得判空~
List<Class<?>> providerDefaultGroupSequence = defaultGroupSequenceProvider.getValidationGroups( beanState );
// 最重要的是这个方法:getValidDefaultGroupSequence对默认值进行分析~~~
return getValidDefaultGroupSequence( beanClass, providerDefaultGroupSequence );
}
return defaultGroupSequence;
}
private static List<Class<?>> getValidDefaultGroupSequence(Class<?> beanClass, List<Class<?>> groupSequence) {
List<Class<?>> validDefaultGroupSequence = new ArrayList<>();
boolean groupSequenceContainsDefault = false; // 标志位:如果解析不到Default这个组 就抛出异常
// 重要
if (groupSequence != null) {
for ( Class<?> group : groupSequence ) {
// 这就是为何我们要`defaultGroupSequence.add(Person.class)`这一句的原因所在~~~ 因为需要Default生效~~~
if ( group.getName().equals( beanClass.getName() ) ) {
validDefaultGroupSequence.add( Default.class );
groupSequenceContainsDefault = true;
}
// 意思是:你要添加Default组,用本类的Class即可,而不能显示的添加Default.class哦~
else if ( group.getName().equals( Default.class.getName() ) ) {
throw LOG.getNoDefaultGroupInGroupSequenceException();
} else { // 正常添加进默认组
validDefaultGroupSequence.add( group );
}
}
}
// 若找不到Default组,就抛出异常了~
if ( !groupSequenceContainsDefault ) {
throw LOG.getBeanClassMustBePartOfRedefinedDefaultGroupSequenceException( beanClass );
}
return validDefaultGroupSequence;
}
到这一步,还仅仅在初始化 BeanMetaData 阶段,就执行了一次(首次) defaultGroupSequenceProvider.getValidationGroups(null) ,所以判空是很有必要的。并且把本class add进默认组也是必须的(否则报错)~到这里 BeanMetaData rootBeanMetaData 创建完成,继续 validate() 的逻辑~
4、 determineGroupValidationOrder(groups) 从调用者指定的分组里确定组序列(组的执行顺序)
ValidatorImpl:
@Override
public final <T> Set<ConstraintViolation<T>> validate(T object, Class<?>... groups) {
...
BeanMetaData<T> rootBeanMetaData = beanMetaDataManager.getBeanMetaData( rootBeanClass );
...
... // 准备好ValidationContext(持有rootBeanMetaData和object实例)
// groups是调用者传进来的分组数组(对应Spring MVC中指定的Group信息~)
ValidationOrder validationOrder = determineGroupValidationOrder(groups);
... // 准备好ValueContext(持有rootBeanMetaData和object实例)
// 此时还是Bean级别的,开始对此bean执行校验
return validateInContext( validationContext, valueContext, validationOrder );
}
private ValidationOrder determineGroupValidationOrder(Class<?>[] groups) {
Collection<Class<?>> resultGroups;
// if no groups is specified use the default
if ( groups.length == 0 ) {
resultGroups = DEFAULT_GROUPS;
} else {
resultGroups = Arrays.asList( groups );
}
// getValidationOrder()主要逻辑描述。此时候resultGroups 至少也是个[Default.class]
// 1、如果仅仅只是一个Default.class,那就直接return
// 2、遍历所有的groups。(指定的Group必须必须是接口)
// 3、若遍历出来的group标注有`@GroupSequence`注解,特殊处理此序列(把序列里的分组们添加进来)
// 4、普通的Group,那就new Group( clazz )添加进`validationOrder`里。并且递归插入(因为可能存在父接口的情况)
return validationOrderGenerator.getValidationOrder( resultGroups );
}
到这 ValidationOrder (实际为 DefaultValidationOrder )保存着调用者调用 validate() 方法时传入的 Groups 们。分组序列 @GroupSequence 在此时会被解析。到了 validateInContext( ... ) 就开始拿着这些Groups分组、元信息开始对此Bean进行校验了~
5、 validateInContext( ... ) 在上下文(校验上下文、值上下文、 指定的分组里 )对此Bean进行校验
ValidatorImpl:
private <T, U> Set<ConstraintViolation<T>> validateInContext(ValidationContext<T> validationContext, ValueContext<U, Object> valueContext, ValidationOrder validationOrder) {
if ( valueContext.getCurrentBean() == null ) { // 兼容整个Bean为null值
return Collections.emptySet();
}
// 如果该Bean头上标注了(需要defaultGroupSequence处理),那就特殊处理一下
// 本例中我们的Person肯定为true,可以进来的
BeanMetaData<U> beanMetaData = valueContext.getCurrentBeanMetaData();
if ( beanMetaData.defaultGroupSequenceIsRedefined() ) {
// 注意此处又调用了beanMetaData.getDefaultGroupSequence()这个方法,这算是二次调用了
// 此处传入的Object哟~这就解释了为何在判空里面的 `年龄为:xxx`被打印了两次的原因
// assertDefaultGroupSequenceIsExpandable方法是个空方法(默认情况下),可忽略
validationOrder.assertDefaultGroupSequenceIsExpandable( beanMetaData.getDefaultGroupSequence( valueContext.getCurrentBean() ) );
}
// ==============下面对于执行顺序,就很重要了===============
// validationOrder装着的是调用者指定的分组(解析分组序列来保证顺序~~~)
// 需要特别注意:光靠指定分组,是无序的(不能保证校验顺序的) 所以若指定多个分组需要小心求证
Iterator<Group> groupIterator = validationOrder.getGroupIterator();
// 按照调用者指定的分组(顺序),一个一个的执行分组校验。
while ( groupIterator.hasNext() ) {
Group group = groupIterator.next();
valueContext.setCurrentGroup(group.getDefiningClass()); // 设置当前正在执行的分组
// 这个步骤就稍显复杂了,也是核心的逻辑之一。大致过程如下:
// 1、拿到该Bean的BeanMetaData
// 2、若defaultGroupSequenceIsRedefined()=true 本例Person标注了provder注解,所以有指定的分组序列的
// 3、根据分组序列的顺序,挨个执行分组们(对所有的约束MetaConstraint都顺序执行分组们)
// 4、最终完成所有的MetaConstraint的校验,进而完成此部分所有的字段、方法等的校验
validateConstraintsForCurrentGroup( validationContext, valueContext );
if ( shouldFailFast( validationContext ) ) {
return validationContext.getFailingConstraints();
}
}
... // 和上面一样的代码,校验validateCascadedConstraints
// 继续遍历序列:和@GroupSequence相关了
Iterator<Sequence> sequenceIterator = validationOrder.getSequenceIterator();
...
// 校验上下文的错误消息:它会把本校验下,所有的验证器上下文ConstraintValidatorContext都放一起的
// 注意:所有的校验注解之间的上下文ConstraintValidatorContext是完全独立的,无法互相访问通信
return validationContext.getFailingConstraints();
}
that is all. 到这一步整个校验就完成了,若不快速失败,默认会拿到 所有 校验失败的消息。
真正执行 isValid 的方法在这里:
public abstract class ConstraintTree<A extends Annotation> {
...
protected final <T, V> Set<ConstraintViolation<T>> validateSingleConstraint(
ValidationContext<T> executionContext, // 它能知道所属类
ValueContext<?, ?> valueContext,
ConstraintValidatorContextImpl constraintValidatorContext,
ConstraintValidator<A, V> validator) {
boolean isValid;
// 解析出value值
V validatedValue = (V) valueContext.getCurrentValidatedValue();
// 把value值交给校验器的isValid方法去校验~~~
isValid = validator.isValid(validatedValue,constraintValidatorContext);
...
if (!isValid) {
// 校验没通过就使用constraintValidatorContext校验上下文来生成错误消息
// 使用上下文是因为:毕竟错误消息可不止一个啊~~~
// 当然此处借助了executionContext的方法~~~内部其实调用的是constraintValidatorContext.getConstraintViolationCreationContexts()这个方法而已
return executionContext.createConstraintViolations(valueContext, constraintValidatorContext);
}
}
}
至于上下文 ConstraintValidatorContext 怎么来的,是new出来的: new ConstraintValidatorContextImpl( ... ) , 每个字段的一个校验注解对应一个上下文 (一个属性上可以标注多个约束注解哦~),所以此上下文是有很强的 隔离性 的。
ValidationContext validationContext和ValueContext valueContext它哥俩是类级别的,直到ValidatorImpl.validateMetaConstraints方法开始一个一个约束器的校验~自定义注解中只把
ConstraintValidatorContext上下文给调用者使用,而并没有给validationContext和valueContext,我 个人觉得 这个设计是不够灵活的,无法方便的实现dependOn的效果~
解决网友的问题
我把这部分看似是本文最重要的引线放到最后,是因为我觉得我的描述已经解决这一类问题,而不是只解决了这一个问题。
回到文首截图中热心网友反应的问题,只要你阅读了本文,我十分坚信你已经有办法去使用 Bean Validation 优雅的解决了。如果各位没有意见,此处我就略了~
总结
本文讲述了使用 @GroupSequenceProvider 来解决多字段联合逻辑校验的这一类问题,这也许是曾经很多人的开发痛点,希望本文能帮你一扫之前的障碍,全面拥抱 Bean Validation 吧~本文我也传达了一个观点:相信流行的开源东西的优秀,不是非常极端的case,深入使用它能解决你绝大部分的问题的。
相关阅读
【小家Spring】@Validated和@Valid的区别?教你使用它完成Controller参数校验(含级联属性校验)以及原理分析
【小家Spring】Bean Validation完结篇:你必须关注的边边角角(约束级联、自定义约束、自定义校验器、国际化失败消息…)
【小家Java】深入了解数据校验:Java Bean Validation 2.0(JSR303、JSR349、JSR380)Hibernate-Validation 6.x使用案例
作者:YourBatman
原文:解决多字段联合逻辑校验问题【享学Spring MVC】 - 掘金