SpringBoot+HikariCP+beetlsql高性能组合更优雅的实现多数据源分页更加丝滑
大家都在用jpa、mybatis,这里分享一个更加出色的高性能组合。自带分页组件,使用从未如此顺滑~
我们使用 https://start.springboot.io 生成基础工程,选择必要的组件进行下载。
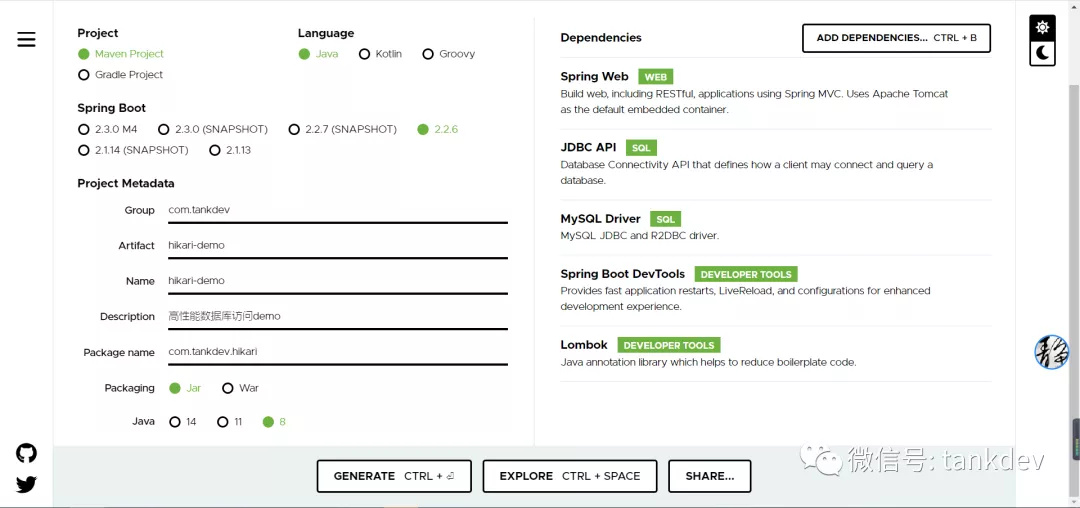
HikariCP
选择一个好的数据库连接池对数据库访问至关重要,Spring Boot 自带 HikariCP 数据库连接池,并推荐优先使用 HikariCP。从下图可以验证 Spring Boot 默认支持。
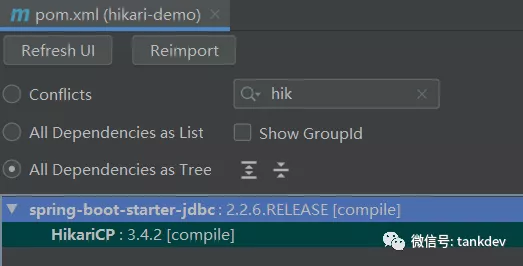
安装HikariCP
Java 8 thru 11 maven artifact:
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.3</version>
</dependency>
Java 7 maven artifact (maintenance mode):
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP-java7</artifactId>
<version>2.4.13</version>
</dependency>
Java 6 maven artifact (maintenance mode):
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP-java6</artifactId>
<version>2.3.13</version>
</dependency>
BeetlSQL
BeetSql是一个全功能DAO工具, 同时具有Hibernate 优点 & Mybatis优点功能,适用于承认以SQL为中心,同时又需求工具能自动能生成大量常用的SQL的应用。下图从不通纬度对常用ORM框架进行了对比。

安装
maven 方式:
<dependency>
<groupId>com.ibeetl</groupId>
<artifactId>beetl-framework-starter</artifactId>
<version>${最新版本}</version>
</dependency>
官网介绍 Document
准备工作
创建库表结构
使用下面语句创建数据库和表结构
CREATE DATABASE first;
USE first;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
`email` varchar(64) DEFAULT NULL,
`age` int(4) DEFAULT NULL,
`create_date` datetime NULL DEFAULT NULL,
`update_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE DATABASE second;
USE second;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
`email` varchar(64) DEFAULT NULL,
`age` int(4) DEFAULT NULL,
`create_date` datetime NULL DEFAULT NULL,
`update_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
多数据源配置
我们采用 Spring 官网推荐的方式进行
@Configuration
public class DataSourceConfig {
@Bean
@Primary
@ConfigurationProperties("app.datasource.first")
public DataSourceProperties firstDataSourceProperties() {
return new DataSourceProperties();
}
@Bean
@Primary
@ConfigurationProperties("app.datasource.first.configuration")
public HikariDataSource firstDataSource() {
return firstDataSourceProperties().initializeDataSourceBuilder().type(HikariDataSource.class).build();
}
@Bean
@ConfigurationProperties("app.datasource.second")
public DataSourceProperties secondDataSourceProperties() {
return new DataSourceProperties();
}
@Bean
@ConfigurationProperties("app.datasource.second.configuration")
public HikariDataSource secondDataSource() {
return secondDataSourceProperties().initializeDataSourceBuilder().type(HikariDataSource.class).build();
}
@Bean
public BeetlSqlDataSource beetlSqlDataSource(@Qualifier("firstDataSource") DataSource firstDataSource,
@Qualifier("secondDataSource") DataSource secondDataSource) {
BeetlSqlDataSource source = new BeetlSqlDataSource();
source.setMasterSource(firstDataSource);
source.setSlaves(new DataSource[]{secondDataSource});
return source;
}
}
application.properties 配置如下
app.datasource.first.url=jdbc:mysql://localhost:3306/first?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false&useInformationSchema=true&allowPublicKeyRetrieval=true
app.datasource.first.username=root
app.datasource.first.password=root
app.datasource.first.configuration.minimum-idle=10
app.datasource.first.configuration.maximum-pool-size=100
app.datasource.first.configuration.connection-timeout=8000
app.datasource.first.configuration.leak-detection-threshold=60000
app.datasource.first.configuration.connection-test-query=SELECT 1
app.datasource.second.url=jdbc:mysql://localhost:3306/second?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false&useInformationSchema=true&allowPublicKeyRetrieval=true
app.datasource.second.username=root
app.datasource.second.password=root
app.datasource.second.configuration.minimum-idle=10
app.datasource.second.configuration.maximum-pool-size=100
app.datasource.second.configuration.connection-timeout=8000
app.datasource.second.configuration.leak-detection-threshold=60000
app.datasource.second.configuration.read-only=true
分页查询
分页查询是我们经常要使用的功能,beetlSql 支持多数据,会自动适配当前数据库生成分页语句,在beeltSql中调用limit方法进行分页。
如果你想直接使用 分页查询同时获得总行数,可以在最后调用page方法,返回一个PageQuery对象。 注意page,与select一样,放在末尾调用,不能重复调用select,page,update,delete之类的哦 使用方法如下:
LambdaQuery<User> query = userDao.createLambdaQuery();
PageQuery<User> page = query.page(1, 2);
System.out.println(page.getTotalRow());
System.out.println(page.getList());
分页从没如此顺滑~
userDao 继承了BaseMapper
功能验证
我们使用单元测试对功能进行验证代码如下
@Test
public void testSaveData() {
List<User> userList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
User u = new User();
u.setAge(102);
u.setName("一个程序猿的异常-master-" + i);
u.setEmail("tankdev@163.com");
userList.add(u);
}
userDao.insertBatch(userList);
}

然后我们查询
first 库,数据也正常插入了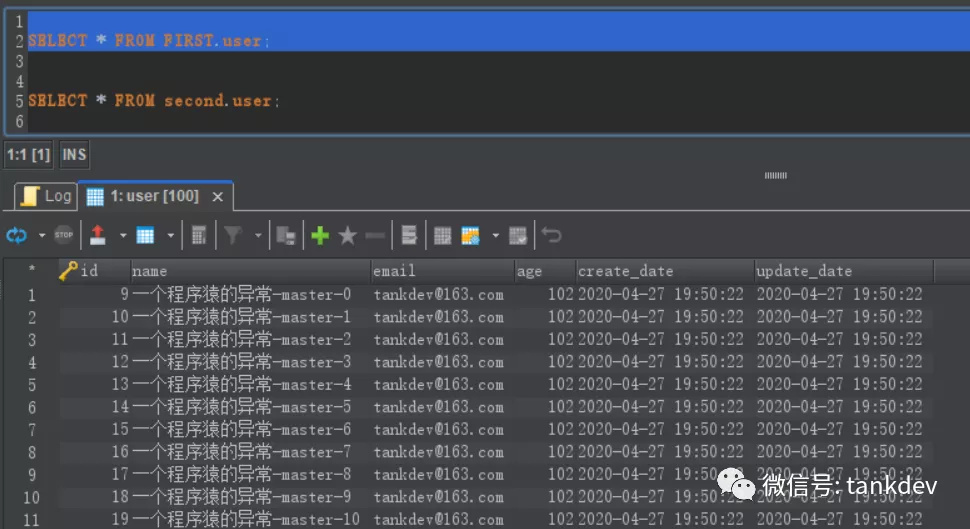
此时我们去
second 查询发现数据不存在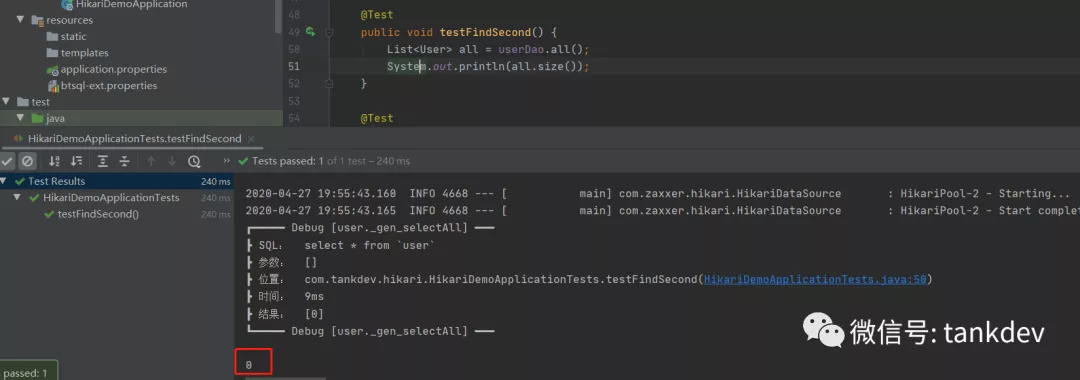
我们用脚本在
second 插入数据再次查询,会发现数据已经存在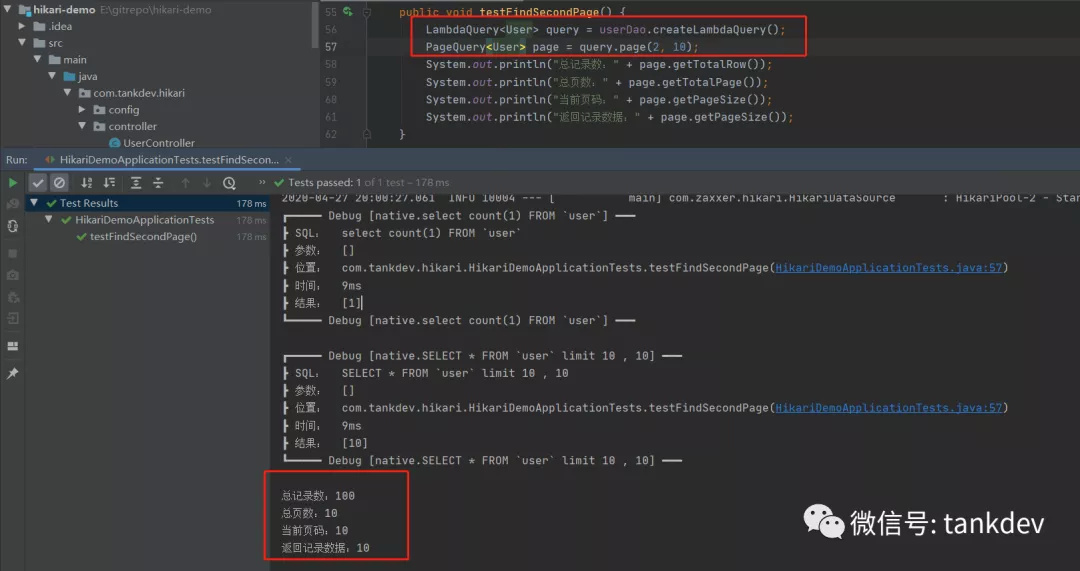
beetl-framework-starter 默认说明
- beetlsql.sqlPath,默认为/sql, 作为存放sql文件的根目录,位于/resources/sql目录下
- beetlsql.nameConversion: 默认是org.beetl.sql.core.UnderlinedNameConversion,能将下划线分割的数据库命名风格转化为java驼峰命名风格,还有常用的DefaultNameConversion,数据库命名完全和Java命名一直,以及JPA2NameConversion,兼容JPA命名
- beetl-beetlsql.dev:默认是true,即向控制台输出执行时候的sql,参数,执行时间,以及执行的位置,每次修改sql文件的时候,自动检测sql文件修改.
- beetlsql.daoSuffix:默认为Dao。
- beetlsql.basePackage:默认为com,此选项配置beetlsql.daoSuffix来自动扫描com包极其子包下的所有以Dao结尾的Mapper类。以本章例子而言,你可以配置“com.bee.sample.ch5.dao”
- beetlsql.dbStyle :数据库风格,默认是org.beetl.sql.core.db.MySqlStyle.对应不同的数据库,其他还有OracleStyle,PostgresStyle,SqlServerStyle,DB2SqlStyle,SQLiteStyle,H2Style
BeetlSQL 功能强大,剩下的功能自己去发现吧