在 SpringBoot中整合ShardingSphere 分库分表
Apache 于北京时间2020年4月15日 宣布 Apache ShardingSphere 毕业成为 Apache顶级项目,
Apache ShardingSphere 是一款分布式数据库中间件,该项目由当当网在 2018年11月10日 捐入 Apache,并在京东数科逐渐发展壮大,成为 业界首个Apache分布式数据库中间件项目。
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC 、 Sharding-Proxy 和 Sharding-Sidecar(规划中) 这3款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
主要分为3个独立的项目
- Sharding-JDBC :定义为轻量级Java框架,在Java的JDBC层提供额外的服务,完全兼容各种ORM框架
- Sharding-Proxy :定位为数据库代理端,我们的项目通过它去访问数据库,统一管理配置
- Sharding-Sidecar(规划中):用于K8S上的
本篇主要讲解 通过Sharding-JDBC 的使用去实现分库分表
1. 准备环境
- Apache ShardingSphere 作为分库分表中间件
-
SpringData+JPA 作为数据访问层
* ```
Docker + Mysql 数据库
1. 创建项目配置依赖
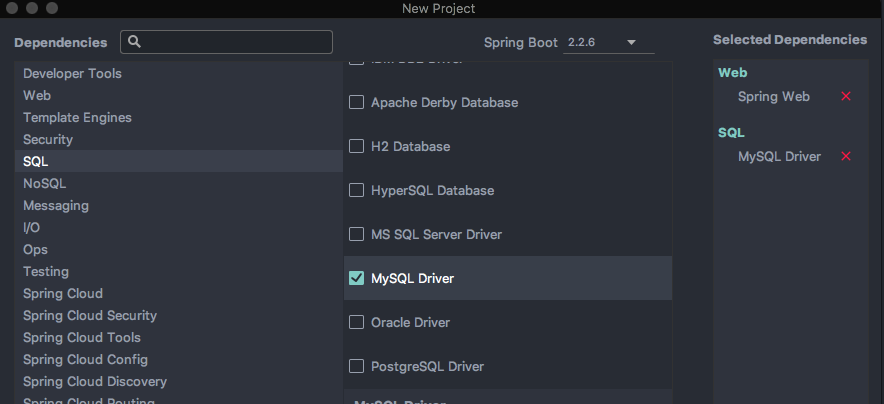
1.1 创建一个SpringBoot项目
勾选Web环境和Mysql 驱动
1.2 添加 Sharding-JDBC 依赖 (最新版本4.0.1)
<!-- Apache shardingsphere-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.1</version>
</dependency>
附上POM文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.johnny</groupId>
<artifactId>shardingsphere</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>shardingsphere</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- shardingsphere -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.1</version>
</dependency>
<!-- lombpk -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- starter-data-jpa -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2. 准备2个Mysql数据库
既然要分库 那么先准备 2个Mysql 数据库, 我这里为了方便直接使用Docker 创建2个Mysql,我选择的是mysql5.7版本
2.1 拉取Mysql5.7依赖
docker pull mysql:5.7

2.2 启动Mysql
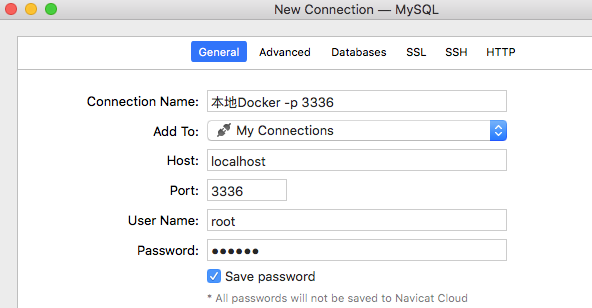
映射端口 3336 初始化密码 123456
docker run -itd --name mysql01 -p 3336:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7

映射端口 3337 初始化密码 123456
docker run -itd --name mysql02 -p 3337:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7

使用数据库连接工具测试一下 连接正常
3. 分库分表配置
3.1 先配置 端口和jpa等基础配置
如果你使用Mybatis可以直接配置Mybatis的配置 因为Sharding-JDBC在DataSource之上的一层 不关心你使用什么ORM
server:
port: 6018
spring:
application:
name: ShardingSphere
jpa:
database: mysql
show-sql: true
open-in-view: true
hibernate:
ddl-auto: update
naming:
strategy: org.hibernate.cfg.DefaultComponentSafeNamingStrategy
properties:
hibernate:
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
format_sql: true
3.2 实体订单表Order和Repository
/**
* 订单表
*
* @author johnny
* @create 2020-04-23 下午1:07
**/
@Data
@Table(name = "tb_order")
@Entity
public class Order implements Serializable {
@Column(name = "id")
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "order_id")
private Long orderId;
@Column(name = "order_name")
private String orderName;
@Column(name = "user_id")
private Long userId;
}
/**
* @author johnny
* @create 2020-04-23 下午1:12
**/
public interface OrderRepository extends JpaRepository<Order, Long> {
}
3.3 分库分表配置
这里打算分 2个库 和 2个表
order0 → order0.tb_order0 order0.tb_order1
order1-> order1.tb_order1 order1.tb_order1
spring:
shardingsphere: #不是spring.datasouce,而是 spring.shardingsphere.datasouce 说明在datasouce上层
props:
sql:
show: true
datasource:
names: ds0,ds1 #数据库名称 分片策略时候使用
ds0:
type: com.zaxxer.hikari.HikariDataSource #配置数据库连接池,你可以选择 你喜欢的DBCP,C3P0等
driver-class-name: com.mysql.jdbc.Driver #Mysql数据库驱动
jdbc-url: jdbc:mysql://127.0.0.1:3336/order0? useUnicode=true&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF-8&characterSetResults=UTF-8&autoReconnect=true&useSSL=false
#docker安装的mysql地址 数据库order0 需要手动先创建好
username: root
password: 123456
hikari:
minimum-idle: 5
idle-timeout: 600000
maximum-pool-size: 10
auto-commit: true
pool-name: MyHikariCP
max-lifetime: 1800000
connection-timeout: 30000
connection-test-query: SELECT 1
ds1: #和上面一样
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://127.0.0.1:3337/order1?useUnicode=true&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF-8&characterSetResults=UTF-8&autoReconnect=true&useSSL=false
username: root
password: 123456
hikari:
minimum-idle: 5
idle-timeout: 600000
maximum-pool-size: 10
auto-commit: true
pool-name: MyHikariCP
max-lifetime: 1800000
connection-timeout: 30000
connection-test-query: SELECT 1
#重要!
sharding:
default-database-strategy: #数据库的分片策略 ,我这里根据 user_id % 2去 分片到不同的数据库
inline:
sharding-column: user_id #分片的 列
algorithm-expression: ds$->{user_id % 2} #具体的分片算法 这是 groovy语法
binding-tables: tb_order #需要分片的 表
tables:
tb_order:
actual-data-nodes: ds$->{0..1}.tb_order$->{0..1} #实际表选择的节点
table-strategy.inline.sharding-column: order_id #表分片的列
table-strategy.inline.algorithm-expression: tb_order$->{order_id % 2} #分表的算法和上面类型
大致意思就是 先配置 2个数据源 ,然后配置 数据库的分片策略 ,再配置 Order表的分片策略 ,还是很简单的 仔细看看
4. 编写测试类 ,测试分库分表
@SpringBootTest
class ShardingsphereApplicationTests {
@Autowired
private OrderRepository orderRepository;
@Test
void testInsert() {
//根据策略 会被定位到 ds1.tb_order1
Order order = new Order();
order.setUserId(1L); //userId 1 % 2 = 1 会分到 ds1 数据库
order.setOrderId(1L); //orderId 1 % 2 = 1 会被分到 tb_order1 数据表
order.setOrderName("Apache ShardingSphere 入门与精通");
//根据策略 会被定位到 ds0.tb_order0
Order order1 = new Order();
order1.setUserId(2L); //userId 2 % 2 = 0 会分到 ds0 数据库
order1.setOrderId(2L); //orderId 2 % 2 = 0 会被分到 tb_order0 数据表
order1.setOrderName("Kotlin 入门到精通");
orderRepository.save(order);
orderRepository.save(order1);
System.out.println(orderRepository);
}
}
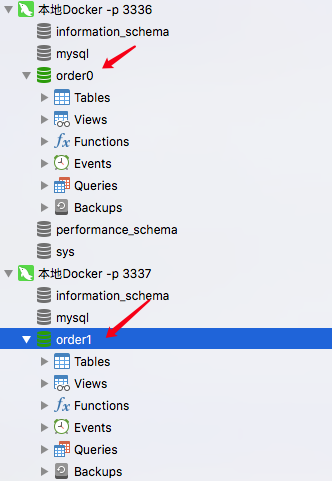
运行前 先创建 Order0 Order1 数据库
Log打印 先打印我们配置的分片规则
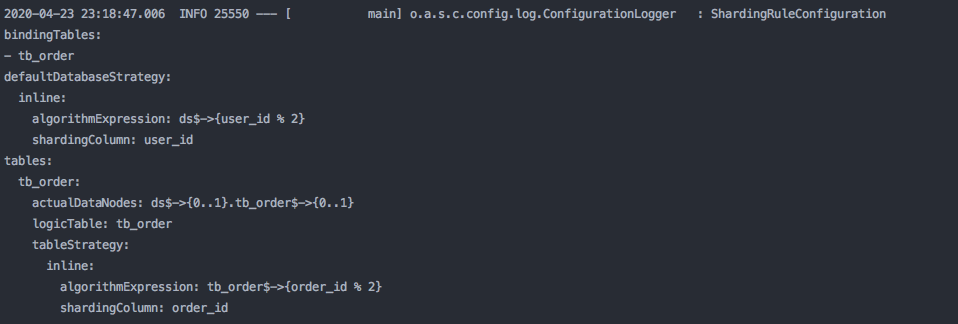
JPA会自动创建表,根据分片策略 会在 2个数据库里创建 4个表
order0 → order0.tb_order0 order0.tb_order1
order1-> order1.tb_order1 order1.tb_order1
Hibernate:
create table tb_order (
id bigint not null auto_increment,
order_id bigint,
order_name varchar(255),
user_id bigint,
primary key (id)
) engine=InnoDB
2020-04-23 23:18:49.586 INFO 25550 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2020-04-23 23:18:49.586 INFO 25550 --- [ main] ShardingSphere-SQL : Logic SQL:
create table tb_order (
id bigint not null auto_increment,
order_id bigint,
order_name varchar(255),
user_id bigint,
primary key (id)
) engine=InnoDB
2020-04-23 23:18:49.586 INFO 25550 --- [ main] ShardingSphere-SQL : SQLStatement: CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.ddl.CreateTableStatement@5ce0f50a, tablesContext=TablesContext(tables=[Table(name=tb_order, alias=Optional.absent())], schema=Optional.absent()))
2020-04-23 23:18:49.587 INFO 25550 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 :::
create table tb_order0 (
id bigint not null auto_increment,
order_id bigint,
order_name varchar(255),
user_id bigint,
primary key (id)
) engine=InnoDB
2020-04-23 23:18:49.587 INFO 25550 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 :::
create table tb_order1 (
id bigint not null auto_increment,
order_id bigint,
order_name varchar(255),
user_id bigint,
primary key (id)
) engine=InnoDB
2020-04-23 23:18:49.587 INFO 25550 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 :::
create table tb_order0 (
id bigint not null auto_increment,
order_id bigint,
order_name varchar(255),
user_id bigint,
primary key (id)
) engine=InnoDB
2020-04-23 23:18:49.587 INFO 25550 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 :::
create table tb_order1 (
id bigint not null auto_increment,
order_id bigint,
order_name varchar(255),
user_id bigint,
primary key (id)
) engine=InnoDB
最后打印了 sql语句, 可以看到逻辑sql 还是 insert into tb_order 但是
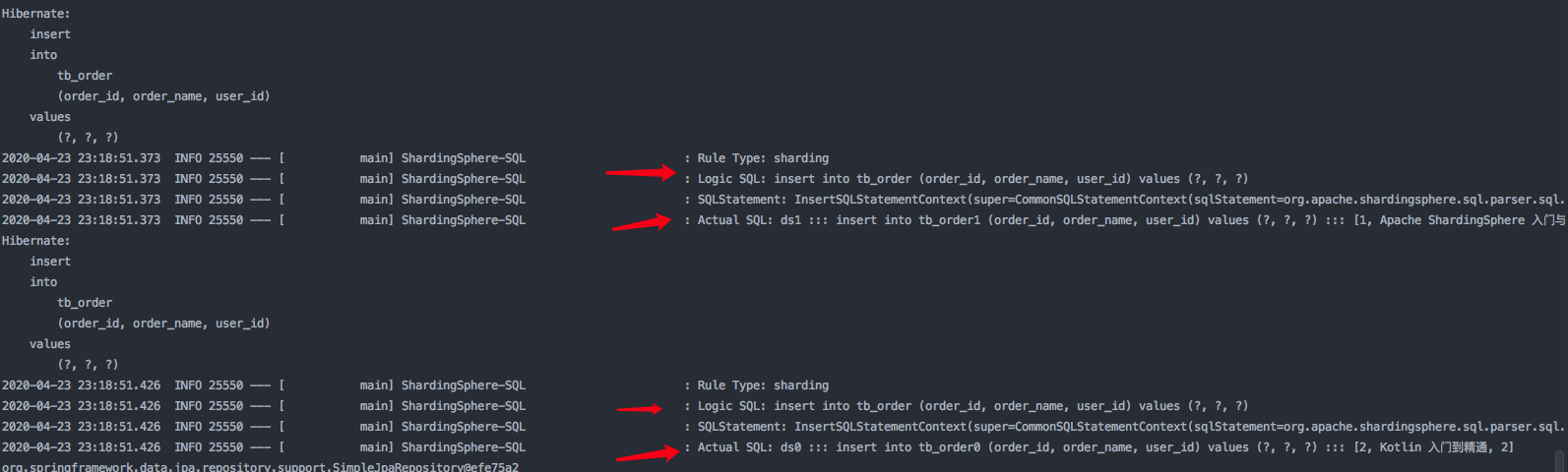
打印日志如下:
Hibernate:
insert
into
tb_order
(order_id, order_name, user_id)
values
(?, ?, ?)
2020-04-23 23:18:51.373 INFO 25550 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2020-04-23 23:18:51.373 INFO 25550 --- [ main] ShardingSphere-SQL : Logic SQL: insert into tb_order (order_id, order_name, user_id) values (?, ?, ?)
2020-04-23 23:18:51.373 INFO 25550 --- [ main] ShardingSphere-SQL : SQLStatement: InsertSQLStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@63f08f9f, tablesContext=TablesContext(tables=[Table(name=tb_order, alias=Optional.absent())], schema=Optional.absent())), columnNames=[order_id, order_name, user_id], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=61, stopIndex=61, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=64, stopIndex=64, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=67, stopIndex=67, parameterMarkerIndex=2)], parameters=[1, Apache ShardingSphere 入门与精通, 1])])
2020-04-23 23:18:51.373 INFO 25550 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 ::: insert into tb_order1 (order_id, order_name, user_id) values (?, ?, ?) ::: [1, Apache ShardingSphere 入门与精通, 1]
Hibernate:
insert
into
tb_order
(order_id, order_name, user_id)
values
(?, ?, ?)
2020-04-23 23:18:51.426 INFO 25550 --- [ main] ShardingSphere-SQL : Rule Type: sharding
2020-04-23 23:18:51.426 INFO 25550 --- [ main] ShardingSphere-SQL : Logic SQL: insert into tb_order (order_id, order_name, user_id) values (?, ?, ?)
2020-04-23 23:18:51.426 INFO 25550 --- [ main] ShardingSphere-SQL : SQLStatement: InsertSQLStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@63f08f9f, tablesContext=TablesContext(tables=[Table(name=tb_order, alias=Optional.absent())], schema=Optional.absent())), columnNames=[order_id, order_name, user_id], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=61, stopIndex=61, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=64, stopIndex=64, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=67, stopIndex=67, parameterMarkerIndex=2)], parameters=[2, Kotlin 入门到精通, 2])])
2020-04-23 23:18:51.426 INFO 25550 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: insert into
查看Mysql 数据库 发现确实分到了不同的库 和不通的表
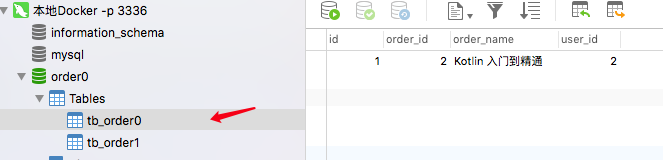
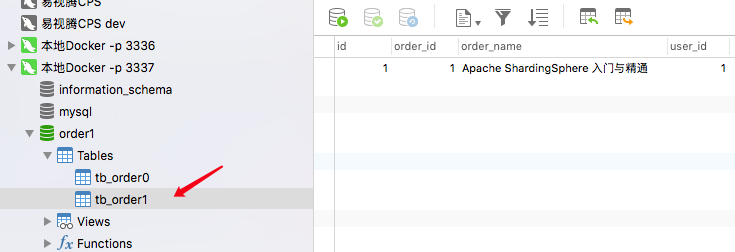
5. 自增主键遗留的问题
由于分到了不同的表,而自增主键会重复 ,导致查询出来后 id 会重复,所以在这种情况下不适合使用自增主键
@Test
void textSelect() {
List<Order> orderList = orderRepository.findAll();
System.out.println(orderList);
}
可以看到 id =1 重复

这时候你可能会想到使用 UUID代替自增注解,其实Mysql是不建议使用UUID作为主键的,过长而且无序会导致查询性能问题,其实有美团提供的
Leaf 基于雪花算法的 分布式主键ID 可以解决这个问题,后面我会写一篇关于Leaf 的文章到时候结合这个
6. 总结
本篇主要讲解 如何使用Sharding-JDBC 去实现 数据库的分库分表操作,其实很简单 主要是分片策略的制定,还遗留了一个关于自增主键ID 的问题, 后续使用 Leaf 替代, 下一篇我会介绍如何使用 Sharding-JDBC 实现读写分离,结合本篇的 分库分表 。
原文:Johnny小屋