背景
使用redis做mq已经不是什么新的技术方案了,各路技术大牛各显神通,奈何实现却良莠不齐,这也导致redis的作者看不下去这种乱象,因此基于redis的代码框架写了一个分布式的mq服务:disque。
岂料disque生不逢时,大家似乎对使用它的热情并没有redis那么强烈,这个项目因此也逐渐处于不维护的状态,虽然redis的作者信誓旦旦说将来要把disque作为redis的一个module来实现,但是大家似乎对redis的module也并不感冒,更不用说这个迁移的实现也遥遥无期。
就在这时,redis5.0的发布,引入了全新的数据结构stream,这个数据结构的出现似乎正是要解决上述使用redis作为mq的乱象,把它作为统一的技术标准。
百家齐放
在stream出现之前,有很多把redis作为mq实现的技术方案,虽然花样繁多,但总结起来以下三种方案是最常见的:
Pub/Sub
这是使用redis作为mq实现最简单的方案。
xxxxxxxxxxxxxxx
x x
+---------------- x x
| Subscribe x Consumer_1 x
| x x
| x x
Channel | xxxxxxxxxxxxxxx
+----------+----------+-----------|
xxxxxxxxxxxx | | | |
x x | | | |
x x Publish | | | |
x Producer x --------------+ A | B | C +
x x | | | |
x x | | | |
xxxxxxxxxxxx | | | |
+----------+----------+-----------+
|
| xxxxxxxxxxxxxxx
| x x
| Subscribe x x
+---------------- x Consumer_2 x
x x
x x
xxxxxxxxxxxxxxx
上述方案非常简单,一个生产者不断向Channel生产消息,若干个消费者从Channel中获取数据,得益于Pub/Sub的模型机制,每个消费者都能从Channel中获取到相同的数据,也就是说Pub/Sub的消息是发散的(Fan Out),每个订阅了Channel的消费者都能从Channel中获取到同等的信息。
可是Redis的Pub/Sub有以下固有的缺点:
- 消息没有持久化的机制。在Pub/Sub模型中,消费者是和连接(Connection)绑定的,当消费者的连接断掉(网络原因或者消费者进程crash)后,再次重连,那么Channel中的消息将永久消失(对于该消费者而言),也就是说Pub/Sub模型缺少消息回溯的机制
- 消费消息的速度和消费者的数量成反比。在Redis的实现中,Redis会把Channel中的消息逐个(Linear)推送给每个消费者,因此当消费者的数量达到一定规模时,服务器的性能将线性下降,因此每个消费者获取到消息的延迟也线性增长
- 当生产者产生消息的速度远大于消费者的消费能力的时候(此时可以简单地理解为消息积压),消费者会被强制断开连接,因此会造成消息的丢失,这个特性可以详见redis的配置
client-output-buffer-limit pubsub 32mb 8mb 60
当消费者的buffer积压超过32MB,或者在60s内消费者的buffer一直保持在8MB以上,那么该消费者就会被redis服务器给强制断开连接,当然你可以修改这个配置,但是会发生难以预料的后果。
通过上述分析可以看到,Redis的Pub/Sub模型非常适合应用在在即时通信、游戏、消息通知等业务上,对于无法容忍数据丢失,消息可能积压的场景不太适合。
List
这是使用redis作为mq最直观的方案。
+------------+-------------+------------+ xxxxxxxxxxxxxx
| | | | x x
xxxxxxxxxxxx | | | | x x
x x | | | | BRPOP x Consumer_1 x
x x + A | B | C +------- x +---------+
x x LPUSH | | | | x x |
x Producer x+------- | | | | x x |
x x | | | | xxxxxxxxxxxxxx |
x x +------------+-------------+-----+------+ |
xxxxxxxxxxxx |
LPUSH |
+-------------------------------------------------------------------------------+
|
| +-------------+-------------+------------+ xxxxxxxxxxxxxxx
| | | | | x x
| | | | | x x
+----- | | | | BRPOP x x
| A | B | C +------- x Consumer_2 x
| | | | x x
| | | | x x
+-------------+-------------+------------+ xxxxxxxxxxxxxxx
上述方案非常直观,毕竟使用List作为消息队列是符合人的直觉的。相比于Pub/Sub,List有以下优点:
- 消息可以持久化。当consumer断开连接或者crash的时候,再次去消费,历史消息会得以保留,可以从最后一次消费的位置进行消费
- 消息可以积压。当生产者产生消息的速度大于消费者的速度的时候,除了会耗费一些内存外,无其他影响
从上面也可以看出,List方案的缺点也非常明显:
- 一个消息最多只能被消费一次。一条消息被一个消费者消费之后,这条消息就被删除了,其他的消费者再无可能重复消费掉这条消息。也就是说List方案的消息不是发散的,同一条消息只能被一个消费者消费
List方案非常适合应用在消息最多被消费一次的场景,如果想要消息被重复消费,需要一些技术手段来解决,常见的有:
- 一个消费者消费完消息之后,把它加入到另外一个队列的对尾,其他消费者从这个新建的队列中消费消息,这样就会造成多个消费者消费的顺序依赖,不能同时干活
- 在消费者消费之前,对消息进行处理,把该消息写入到若干个队列中,这样能支持多个消费者同时消费,但是数据却被拷贝了多次
ZSet
有序集合是上述方案中最复杂的实现方案,但是它能有效地解决Pub/Sub和List方案的不足。
xxxxxxxxxxxxxx
ZRANGEBYSCORE x x
++-----------+ x Consumer_1 x
| x x
xxxxx xxxxxx +-------+-------+-------| xxxxxxxxxxxxxx
x x ZADD | | | +
x Producer +--------- | A | B | C +
x x | | | +
xxxxxxxxxxxx +-------+-------+-------| xxxxxxxxxxxxxx
|ZRANGEBYSCORE x x
++-----------+ x Consumer_2 x
x x
xxxxxxxxxxxxxx
虽然实现起来相对复杂,但是ZSet解决了Pub/Sub和List的种种缺陷,成为在stream出现之前最优秀的mq实现。它有以下优点:
- ZSet支持消息持久化。不同于Pub/Sub,当消费者连接断开或者crash的时候,消费者能够获取到尚未被消费的消息,消息不会丢失
- ZSet支持消息重复消费。不同于List,当一条消息被消费时,这条消息就彻底消失了,ZSet使用的获取消息操作ZRANGEBYSCORE是无害的,该操作不会删除消息
但是ZSet的实现方案要解决以下问题
- 消息的顺序。不同于Pub/Sub和List,它们的消息本身是有序的,ZSet本身是一个set,它存储的消息并不是按照先后顺序来存放的,因此score至关重要,这关系到消息的先后顺序,一种可行的方案是使用timestamp+seq作为score,这样能够保证消息的顺序。
- 重复消息的添加。由于有序集合的限制,重复的消息是不能够添加到集合中的,因此也要解决重复消息(消息内容完全一致)的问题
- 消息索引。必要时要提供一种有效的手段记录消息ID(唯一标识一条消息的ID)和消息内容(Body)的索引
基于上述种种原因,导致ZSet方案的实现相比于前两种相对复杂的多。
应运而生
Redis5.0版本的发布,带来了全新的数据类型stream,该重大更新解决了使用Redis作为mq的很多痛点。
Stream不但克服了上述三种实现方案的种种缺点,而且提供了更加灵活和更丰富的功能,总体来说stream提供了三种工作模式。
在介绍三种模式之前,我们先熟悉一下stream数据类型提供的redis commands,和ZSet一样,所有的命令都以Z开头,stream的所有命令都是以X开头,如果你看到一个redis命令是以X开头的,那毋庸置疑,这个命令是操作stream的。
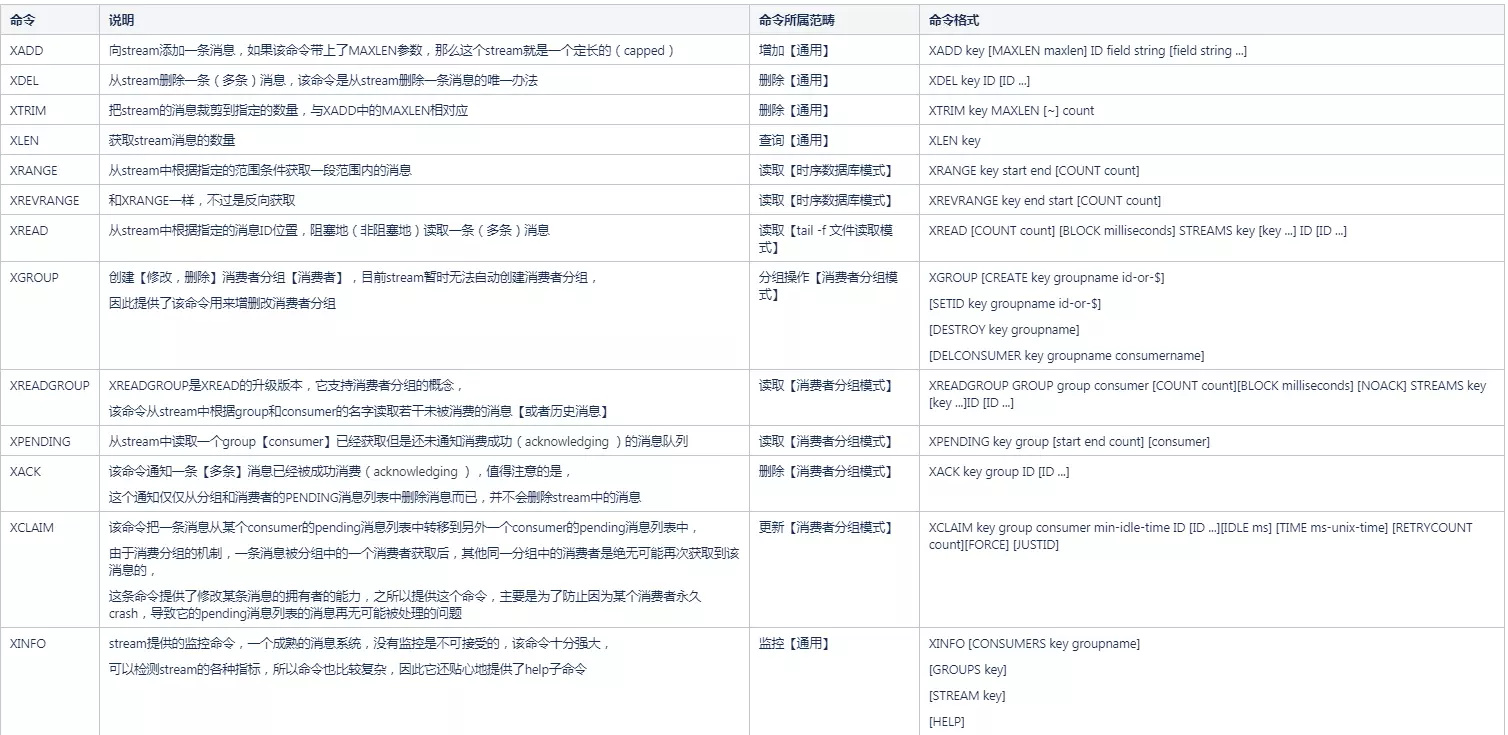
下面我们重点介绍一下XADD命令,虽然这个命令比较简单,但是最重要,毕竟没有插入消息的基本动作其他都免谈,而且这个命令牵涉到很重要的一个概念:消息ID的格式。
XADD key [MAXLEN maxlen] ID field string [field string ...]
example:
#添加一个消息
127.0.0.1:6379> XADD stream_test * name hanyugang age 17
"1542265003725-0"
#获取消息队列中消息的个数
127.0.0.1:6379> XLEN stream_test
(integer) 1
其中stream_test就是key,也就是stream的名字,比较特殊的是ID这个参数,这个参数表示消息的ID,在这里我们使用的是*,这表示使用默认的ID生成方式,也就是redis服务器自己生成的。你可能会问,难道还可以自己定制ID的生成方式?答案是是的。这个稍后再讲。
消息ID的格式
"1542265003725-0" 这个就是服务器返回给我们的消息ID,它其实有两部分组成:时间戳-序号。
时间戳标识消息在什么时间生成,它用redis服务器的时间戳(毫秒级别)来表示,它是个64位整型;序号标识在这个时间点内(其实就是1ms啦),该消息是几条消息,它也是个64位整型。因此如果在一毫秒内产生的消息超过了2^64-1个,那么才会溢出,但是这几乎是不可能的,所以可以忽略这个问题。通过上面的描述可以总结一下这条消息ID的意义就是:这条消息生成时间是1542265003725(2018/11/15 14:56:43.725),并且是在1542265003725-1542265003726时间内的第0条(就是第一条啦,程序员的思维)消息。
Tips:
如果使用redis-cli来验证xadd命令,你几乎总是得到seq=0的消息ID,原因很简单嘛,你敲xadd的命令达不到毫秒级别,可以尝试使用下面的办法:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> xadd stream_test * name hanyugang age 17
QUEUED
127.0.0.1:6379> xadd stream_test * name hanyugang1 age 18
QUEUED
127.0.0.1:6379> xadd stream_test * name hanyugang2 age 19
QUEUED
127.0.0.1:6379> EXEC
1) "1542268298953-0"
2) "1542268298953-1"
3) "1542268298953-2"
消息ID的单调递增
另外值得注意的是,Redis生成的消息ID总是单调递增的,即使由于某种不可预料的原因导致服务器的时间后退了,Redis也能保证生成的消息ID是严单调递增的(如何做到的呢,其实redis内部会为每个stream维护一个latest_generated_id的变量,该变量标记最新的消息ID,如果发现时间戳倒退,redis会使用latest_generated_id中的时间戳,然后只递增seq部分,因此会自动修正这个问题),毕竟这牵涉到消息的顺序问题。
前面讲到了消息ID的自定义问题,您可以自己指定消息的ID,而不是让服务器自己生成,但是您要保证该消息ID是严格单调递增的,否则您在插入下一条消息的时候服务器就会报错。实际上服务器自己生成的ID有诸多的好处和特别的用意,因此Redis的作者也建议不要使用自己指定的ID,使用服务器自己生成的就好了,这几乎总是正确和你想要的。
主从环境下消息ID的一致性
您可能注意到,如果使用*让服务器自己生成ID,那么在主从环境下,如果从库同步的是redis的命令(commands replication),那么从库也会自己生成一个ID,这个ID和主库生成的很可能不一样(时间戳不同,异步复制是需要时间的),其实不用担心这个问题,stream命令的主从复制使用的是effects replication,也就是说从库复制的是展开后的XADD命令,还拿上面的XADD命令举例,从库复制的XADD命令其实是: XADD 1542265003725-0 stream_test name hanyugang age 17 。哈哈,问题搞定,这就保证了在主从环境下,我们消息的ID总是一致的。
上面讲完了如何添加一条消息到stream以及stream的消息ID格式,下面我们就开始谈一下stream的三种典型应用场景(也就是三种工作模式)。
时序数据库模式(infuxdb like)
您可能注意到,消息ID的生成有许多优秀的方案,为什么redis要用时间戳呢?除了时间戳具有先天的单调递增特性,还有其他原因吗?
是的,有其他原因。stream的野心不单单只是消息队列服务,它还可以充当时序数据库的角色。到这里你应该明白了为什么redis的作者强烈推荐在添加消息的时候使用服务器自己生成的消息ID,并且消息的ID格式是timestamp+seq的原因了。
XRANGE和XREVRANGE是实现stream作为时序数据库的两个主要命令。
XRANGE key start end [COUNT count]
127.0.0.1:6379> xrange stream_test - + count 2
1) 1) "1542265003725-0"
2) 1) "name"
2) "hanyugang"
3) "age"
4) "17"
2) 1) "1542268298953-0"
2) 1) "name"
2) "hanyugang"
3) "age"
4) "17"
上面的例子表示:我要获取stream_test这个队列中的数据,消息ID的范围是从最小到最大,并且只获取2个消息。
特别地,xrange命令中的start和end参数中,"-“表示最小的消息ID,”+"表示最大的消息ID。
遍历队列
- 使用 XRANGE key - + COUNT count 试图获取count个消息
- 如果发现返回的消息数量ret<count,那么说明所有的消息已经被获取,迭代结束,转5
- 如果ret==count,那么说明队列中还有元素,记录返回的消息中最后一个消息的ID为last_id,然后继续迭代,使用命令 XRANGE key last_id + COUNT count
- 重复步骤2和3
- 迭代结束
可以看到使用XRANGE去迭代一个队列是非常简单的。
按照时间段采集数据
当然我们也可以像时序数据库那样,采集某个时间段内的数据,因为消息的ID是由时间戳构成的,因此使用XRANGE去采集数据就非常明了,比如我想采集stream_test队列中,2018/11/15 15:51:38-2018/11/15 15:52:38的数据,那么可以使用下面的命令即可
127.0.0.1:6379> XRANGE stream_test 1542268298000 1542268358000
1) 1) "1542268298953-0"
2) 1) "name"
2) "hanyugang"
3) "age"
4) "17"
2) 1) "1542268298953-1"
2) 1) "name"
2) "hanyugang1"
3) "age"
4) "18"
3) 1) "1542268298953-2"
2) 1) "name"
2) "hanyugang2"
3) "age"
4) "19"
您可能也注意到,xrange中的start和end参数,如果没有指定seq部分,在start参数中默认该seq=0,也就是说1542268298000 这个消息ID和1542268298000-0是一样的,在end参数中默认该seq=正无穷,既最大的seq。
XRANGE的效率
由于stream采用radix tree(基数树)来组织,因此,定位start的时间复杂度是 O(log(N)), 返回M个元素的时间复杂度是 O(M) ,因此XRANGE的效率是非常高效的,对数级别。这也是stream为什么没有提供类XSCAN之类的命令,因为XRANGE已经足够高效。
另外还有一个XREVRANGE命令,该命令与XRANGE非常类似,唯一不同的是,它按照相反的顺序返回消息。
从上面的分析可以看到,在某些场景,使用stream的时序数据库模式(只提供了XRANGE采集数据,并没有提供一个成熟的时序数据库具有的聚合分类函数),如果再配合定长队列,非常适合应用在服务器性能统计等业务。
其实,如果仔细分析,可以发现XRANGE提供的时序数据库模式有点类似List提供的部分功能,List也有类似XRANGE的命令LRANGE。因此可以认为stream的时序数据库模式借鉴了List的优点。
tail -f 文件读取模式(tail -f like)
如果您熟悉Linux下面tail工具,你肯定对它记忆犹新,tail工具有以下特点:
- tail -f 可以即时的显示新增的文件内容,如果没有新的内容,则阻塞
- tail -n 可以显示历史的文件内容,其中参数n表示最后n行文件内容,特别地,n的默认值是10
- 多个用户(tty)可以同时使用tail -f工具,而且每个tty都能够显示出新增的文件内容
stream提供了类似tail工具的功能,使用XREAD命令实现,也被称为tail -f 文件读取模式。
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
XREAD提供了阻塞和非阻塞两种读取模式。
非阻塞读取模式
非阻塞模式下的XREAD非常类似文件读取操作,读取消息的个数有COUNT参数指定(如果不指定,则默认读取所有),读取消息的开始位置有ID参数来指定,读取的文件有streams参数指定。
此时可以类比Linux下面的tail -n 命令(不带参数-f),其中-n类比XREAD的COUNT参数。
127.0.0.1:6379> XREAD count 2 streams stream_test 0
1) 1) "stream_test"
2) 1) 1) "1542265003725-0"
2) 1) "name"
2) "hanyugang"
3) "age"
4) "17"
2) 1) "1542268298953-0"
2) 1) "name"
2) "hanyugang"
3) "age"
4) "17"
消息队列遍历
- 使用 XREAD COUNT count STREAMS key 0,试图获取count个消息
- 如果发现返回的消息个数ret<count,那么说明所有的消息已经被读取完毕,迭代结束
- 如果发现返回的消息个数ret==count,那么说明队列中还有元素,记录返回的消息中最后一个消息的ID为last_id,然后继续迭代,使用命令 XREAD COUNT count STREAMS key last_id
- 重复步骤2和3
- 迭代结束
可以看到,非阻塞模式下的XREAD遍历消息队列非常类似文件的读取操作。
特别地,XREAD的ID参数表示读取的起始位置,0表示最小的消息ID,类似文件的开头,$表示最新的消息ID,类似文件的结尾。对于非阻塞模式来说$参数是无意义的,因为读取的消息总是为空。
阻塞模式
阻塞模式下的XREAD命令除了消息队列中没有数据时会阻塞客户端之外和非阻塞的XREAD并无区别,利用XREAD的block特性,可以很方便地实现类似Linux上tail -f的命令
#在一个tty中执行阻塞的XREAD命令,其中block的参数0表示永远不超时,如果大于0,则表示过了多久就会超时返回(毫秒级别)
127.0.0.1:6379> XREAD block 0 streams stream_test $
#此时并没有新的消息加入,因此该命令阻塞
#在另外一个tty执行XADD命令
127.0.0.1:6379> XADD stream_test * name hanyugang age 16
"1542333943525-0"
#此时被阻塞的XREAD命令返回
1) 1) "stream_test"
2) 1) 1) "1542333943525-0"
2) 1) "name"
2) "hanyugang"
3) "age"
4) "16"
(43.51s)
#可以看到XREAD阻塞了43.51s后返回
利用XREAD实现tail -f的伪代码
latest_id := "$"
for {
message_list, err := $( XREAD BLOCK 10000 STREAMS key latest_id)
if err !=nil {
if err == timeout{
continue
}else {
printf("xread failed, err:", err)
break
}
}
printf("we got messages:", message_list)
for _, message := range message_list {
process_message(message)
}
latest_id = message_list[len(message_list)-1].message_id
}
针对XREAD命令,有一些细节需要注意一下
- 在阻塞模式下,如果参数ID指定为$,那么XREAD的COUNT参数不起作用,即使你指定COUNT的值,在该情形下,只要有一条数据返回,XREAD的阻塞模式就会被解除,从而整个命令返回,因此阻塞模式下的XREAD无法实现诸如我要等待10条数据,当10条数据都到来时才解除阻塞返回,这是做不到的。因此不建议在XREAD的阻塞模式下并且ID参数指定为$时使用COUNT参数,虽然无害(因为不起作用嘛),但是容易造成误解
- 在阻塞模式下,XREAD的ID参数比较常用的是$,它表示最新的消息ID,可以实现类似tail -f的效果,但并不是说在阻塞模式下,只能使用$,所有的合法消息ID都可以使用,只要从这个指定的ID以后有数据,那么XREAD就返回,否则就阻塞,直到数据到来。需要注意的是,在阻塞模式下如果指定的ID不是$,比如是0,并且stream中有数据可读,此时阻塞模式可以简单地认为退化成非阻塞模式,COUNT参数起作用
- XREAD命令本身支持从多个streams读取消息,假设有多个stream(比如有2个stream,key分别是stream_1和stream_2)。在非阻塞模式下,那么它实现的原意是:从stream_1和stream_2分别读取COUNT参数指定个数的消息;在阻塞模式下,它实现的原意是:在stream_1和stream_2上等待数据,如果任意一个stream中有一条数据到来,那么阻塞解除,XREAD命令返回
- 既然XREAD支持多个streams,那么在集群环境下,要注意所有的stream的key必须在同一个slot上,否则报错。相对的,redis集群对Pub/Sub系列命令做了特殊处理,所以可以支持跨slot的channel
消费者组模式(kafka like)
为了实现更精细的消费控制,stream实现了类似kafka的消费者分组的功能。
消费者分组
顾名思义,消费者分组就是把若干的消费者放在一起组成一个概念上的分组。消费者分组保证了以下特性
- 不同的消费者(通过消费者ID区分)互不影响,相互隔离,它们彼此看不到各自的历史消费消息
- 不同的消费者(通过消费者ID区分)只能看到整个消息队列的一部分消息,也就是说一个消费者只消费整个消息队列的一个子集,并且这些子集绝不会出现重合的消息
- 所有消费者消费的消息子集的交集就是整个消息队列集合
从上面可以看出,消费者分组实际上是把一个大的消息集合分而治之,分组中的每一个消费者只负责整个消息集合中的一个子集,并且能够保证同一分组中的不同消费者不会重复消费同一条消息。同一分组中的消费者彼此独立,又相互协作配合,从而完成整个消费队列的消费工作。
使用消费者分组有以下好处
- 相比于多个同等的消费者去消费一个大的消息队列,消费者分组划分更为精细,从而减缓了多个消费者之间的数据竞争
- 如果消息队列在存储的时候是按照多分区(multi partition)进行组织的,那么同一分组中的不同消费者可以负责不同的分区数据,在这种情况下,不但从算法逻辑上分而治之,在物理存储上也实现了分而治之,因此更加高效
Redis Stream消费者分组的一个例子
假设现在有一个消费者分组G,该分组下面共有3个消费者C1,、C2、C3。一个消息队列S中共有7条消息1、2、3、4、5、6、7,那么一种可能的消费方式如下
1 → C1
2 → C2
3 → C3
4 → C1
5 → C2
6 → C3
7 → C1
可以看到C1消费了1、4、7,C2消费了2、5,C3消费了3、6。但是绝不可能出现C1消费了1,C2也消费了1。
+----------------------------------------+
| consumer_group_name: mygroup |
| consumer_group_stream: somekey |
| last_delivered_id: 1292309234234-92 |
| |
| consumers: |
| consumer-1 with pending messages |
| 1292309234234-4 |
| 1292309234232-8 |
| consumer-2 with pending messages |
| ... (and so forth) |
+----------------------------------------+
其中last_delivered_id是最重要的数据,它表示当前group最后消费的那条消息的ID,不同的消费者是如何做到消费的消息不重复的,主要原因就是last_delivered_id的存在,消费者从队列中获取还未被消费的消息的时候,都会从last_delivered_id这个位置开始(不包含),因此只要last_delivered_id这个位置信息个值随着变化,不同的消费者获取到的消息就不会重复。
每个consumer中都有个pending messages列表,这个消息列表代表的是:已经被consumer获取,但是还未被consumer通知该消息已经被成功处理的消息列表。您可能会问为什么需要这个pending列表,除了浪费内存并没有什么大的用处,其实不然。考虑一下这种情况,consumer_A获取了1,2,3,4一共四条消息,其中在处理消息1的时候,由于种种原因消费者程序crash,如果没有一种回溯机制让consumer_A在重新启动的时候能够获取到自己的pending消息列表,那么1,2,3,4这四条消息将永远的消失了,因为该分组中的其他消费者是不可能重复消费到这4条消息的。所以pending消息列表在保证数据完整性上是必不可少的。另外值得一提的是除了每个consumer会有一个pending消息列表外,消费者分组本身也有个pending消息列表,毋庸置疑,这个消息列表就是该分组下面所有consumer的pending消息列表集合。
升级版的XREAD
stream提供的消费者分组模式使用XREADGROUP实现,XREADGROUP是XREAD命令的升级版,您可以认为它是添加了GROUP功能的XREAD命令。
创建消费者分组
在使用XREADGROUP命令之前,您要先创建分组,是的,目前分组无法自动创建,必须手动创建。
XGROUP [CREATE key groupname id-or-$]
[SETID key groupname id-or-$]
[DESTROY key groupname]
[DELCONSUMER key groupname consumername]
可以看到,XGROUP提供了一组子命令用来创建/删除/修改分组,另外还可以删除一个分组中的消费者。您可能会问为什么没有创建/修改消费者的命令呢,因为消费者会自动创建,而且消费者也无需修改,所以只有删除消费者的命令咯。
XGROUP CREATE stream_test group_test 0
上面的命令在stream_test这个stream上创建了一个叫做group_test的消费者分组,当该分组的消费者读取stream_test中消息的时候,读取的起始位置是0。是的,在创建消费者分组的时候您要指定读取消息的起始位置,这个位置可以是普通的消息ID,比如1542275910096-0,也可以是0,表示最小的消息ID,也可以是$,表示最后一个消息的ID。值得注意的是,一个消费者分组不能被重复创建,如果发现groupname已经存在,服务器会报错:(error) BUSYGROUP Consumer Group name already exists。
明白了在创建消息分组的时候要指定ID参数,那么也就理解了XGROUP为什么会提供SETID子命令了,该命令用来修改消息分组创建的时候指定的ID参数,下面的命令把消费者分组读取消息的起始位置修改为$.
XGROUP SETID stream_test group_test $
和CREATE子命令向呼应,DESTROY子命令用来删除一个消费者分组
XGROUP DESTROY stream_test group_test
对于删除消费者的子命令这里就不举例了。
使用消费者分组进行消费数据
前面提到了XREADGROUP其实就是XREAD的升级版,前者带上了消费者分组的功能而已。
XREADGROUP GROUP group consumer [COUNT count][BLOCK milliseconds] [NOACK] STREAMS key [key ...]ID [ID ...]
可以看到相比XREADGROUP除了GROUP关键字和group参数以及comsuer的参数,其他和XREAD几乎一模一样。
值得注意的是XREADGROUP的ID参数和XREAD的ID参数意义不太相同。XREAD的ID参数表示开始读取消息的位置,XREADGROUP的ID参数有更复杂的含义
- 当ID是特殊字符>时,XREADGROUP从队列中读取从未被消费过的消息,也就是语意上的“newer message”,此时特殊ID“>”的意义也就不言而喻了,它表示消息队列中从未被消费过消息的起始位置,如果你看了前面的介绍,你应该清楚这个特殊的ID其实就是last_delivered_id
- 当ID不是特殊字符>时,XREADGROUP的语意发生了变化,不再是从消息队列中读取消息,而是从consumer的pending消息列表中读取历史消息
下面我们看一个例子吧
#添加一些消息到队列stream_fruit
127.0.0.1:6379> xadd stream_fruit * message apple
"1542355396362-0"
127.0.0.1:6379> xadd stream_fruit * message banana
"1542355421051-0"
127.0.0.1:6379> xadd stream_fruit * message orange
"1542355427899-0"
127.0.0.1:6379> xadd stream_fruit * message pear
"1542355436365-0"
127.0.0.1:6379> xadd stream_fruit * message strawberry
"1542355444220-0"
#创建消费者分组fruit_group,消费者分组的消息读取起始位置为0,即队列的最开始处
127.0.0.1:6379> XGROUP create stream_fruit fruit_group 0
OK
#使用consumer_1消费者消费2条消息
127.0.0.1:6379> XREADGROUP group fruit_group consumer_1 count 2 streams stream_fruit >
1) 1) "stream_fruit"
2) 1) 1) "1542355396362-0"
2) 1) "message"
2) "apple"
2) 1) "1542355421051-0"
2) 1) "message"
2) "banana"
#可以看到,队列中的前2条消息已经被消费
#使用consumer_2消费者消费2条消息
127.0.0.1:6379> XREADGROUP group fruit_group consumer_2 count 2 streams stream_fruit >
1) 1) "stream_fruit"
2) 1) 1) "1542355427899-0"
2) 1) "message"
2) "orange"
2) 1) "1542355436365-0"
2) 1) "message"
2) "pear"
#可以看到第3,4两条消息被consumer_2给消费掉了
#使用consumer_3消费者消费2条消息
127.0.0.1:6379> XREADGROUP group fruit_group consumer_3 count 2 streams stream_fruit >
1) 1) "stream_fruit"
2) 1) 1) "1542355444220-0"
2) 1) "message"
2) "strawberry"
#可以看到最后1条消息被consumer_3给消费掉了
#下面我们查看一下consumer_1的pending消息队列中的历史消息
127.0.0.1:6379> XREADGROUP group fruit_group consumer_1 count 2 streams stream_fruit 0
1) 1) "stream_fruit"
2) 1) 1) "1542355396362-0"
2) 1) "message"
2) "apple"
2) 1) "1542355421051-0"
2) 1) "message"
2) "banana"
当consumer获取到消息之后,stream就会把这条消息加入到pending消息列表,如果这条消息被consumer成功处理,这个时候应该有一种机制来通知消费者分组这条消息被成功消费了,你应该把它从consumer的pending消息列表中删除,不然一条消息就会占用2倍的内存了(stream中保存一份,consumer的pending消息列表中保存一份)。的确,stream提供了这个机制XACK
XACK key group ID [ID ...]
可以看到XACK命令非常简单。下面我们演示一下XACK的通知效果
127.0.0.1:6379> XREADGROUP group fruit_group consumer_1 count 2 streams stream_fruit 0
1) 1) "stream_fruit"
2) 1) 1) "1542355396362-0"
2) 1) "message"
2) "apple"
2) 1) "1542355421051-0"
2) 1) "message"
2) "banana"
127.0.0.1:6379> XACK stream_fruit fruit_group 1542355396362-0
(integer) 1
127.0.0.1:6379> XREADGROUP group fruit_group consumer_1 count 2 streams stream_fruit 0
1) 1) "stream_fruit"
2) 1) 1) "1542355421051-0"
2) 1) "message"
2) "banana"
127.0.0.1:6379> xrange stream_fruit 1542355396362-0 + count 1
1) 1) "1542355396362-0"
2) 1) "message"
2) "apple"
从上面的例子可以看到,调用XACK之后,consumer_1的pending消息队列的确删掉了消息1542355396362-0,值得注意的是这条消息并没有从消息队列中删除,通过XRANGE命令我们确认了这一点。要想删除消息队列中的消息,我们可以也只能使用XDEL命令。
和XREAD一样XREADGROUP支持两种模式:阻塞和非阻塞。在XREAD中我们已经详细介绍过这两种模式,因此这里不再详述。
对于XREADGROUP的使用有以下细节需要注意一下
- 消费者是在使用的使用自动创建的,它无需向消费者分组那样在使用前需要显式创建
- XREADGROUP虽然是个读取操作,但其实它是一个有害的命令,也就是说它是一个写操作。为什么是个写操作呢,因为在读取的时候,XREADGROUP内部会把读取到的消息添加到消费者的pending消息队列,并且会修改消费者分组中的last_delivered_id等数据结构,所以这是一个写命令,如果在开启了读写分离的环境中,这个命令只能在master节点上进行操作
- XREADGROUP支持多个streams的读取,但是有一个前提条件:所有的streams都预先创建了同名的消费者分组
使用消费者分组实现一个典型的消费者程序
require 'redis'
if ARGV.length == 0
puts "Please specify a consumer name"
exit 1
end
ConsumerName = ARGV[0]
GroupName = "mygroup"
r = Redis.new
def process_message(id,msg)
puts "[#{ConsumerName}] #{id} = #{msg.inspect}"
end
$lastid = '0-0'
puts "Consumer #{ConsumerName} starting..."
check_backlog = true
while true
# Pick the ID based on the iteration: the first time we want to
# read our pending messages, in case we crashed and are recovering.
# Once we consumer our history, we can start getting new messages.
if check_backlog
myid = $lastid
else
myid = '>'
end
items = r.xreadgroup('GROUP',GroupName,ConsumerName,'BLOCK','2000','COUNT','10','STREAMS',:my_stream_key,myid)
if items == nil
puts "Timeout!"
next
end
# If we receive an empty reply, it means we were consuming our history
# and that the history is now empty. Let's start to consume new messages.
check_backlog = false if items[0][1].length == 0
items[0][1].each{|i|
id,fields = i
# Process the message
process_message(id,fields)
# Acknowledge the message as processed
r.xack(:my_stream_key,GroupName,id)
$lastid = id
}
end
和kafka的消费者分组的不同
上面介绍了stream的消费者分组模式的使用,提到消费者分组,很多人可能会想到kafka,那么stream的消费者分组和kafka有何不同呢?
- stream实现的消费者分组只是“逻辑上”的,是个“虚假”分组概念,原因很简单,redis的stream(代表一个消息队列)只是一个简单的key而已,和普通的字符串的key并无区别,即使消费者分组把消费者进行逻辑上的划分,但是始终没有改变多个消费者向同一个stream去竞争数据的事实。而kafka的topic(代表一个消息队列)在内部存储的时候会划分成多个partition(分区),因此kafka的消费者分组中的消费者可以针对不同的partition进行消费,比如消费者分组中的consumer_1负责partition)1的数据,consumer_2负责partition_2上的数据,因此kafka的消费者分组的实现更加纯粹,更加“真实”,不但从逻辑上实现了精细的划分,而且在物理上也实现了更加精细的划分
- 当stream中的某些消费者宕机时,redis服务对其并无感知,就好像这些宕机的消费者进程不存在似得,无需任何的干预,剩余的消费者一样能把整个消息队列给消费完,但是kafka实现的消费者分组在某些消费者宕机时,服务器会自动把宕机的消费者负责的partition自动分配给其他消费者,即所谓的“失败转移”,因此kafka的实现比起redis的实现要复杂很多
- 我们可以使用redis cluster或者其他分布式的redis集群系统,把单个stream的key划分成多个key,这样就能实现kafka的multi partition的概念,从而增强stream的吞吐量,但是你要注意的是,由于redis cluster的诸多限制(其实最大的限制是那些操作多个key的命令,这些key必须位于同一个hash slot上面),你要合理地分配多个key的存储位置以及解决多个key不再同一台机器的访问限制问题
由于XREADGROUP是stream最复杂的命令,对于一个新的数据类型而言,目前redis5.0版本还是有挺多的BUG,本人在测试试用的过程中也碰到一些问题,都是关于XREADGROUP的,详见issuehttps://github.com/antirez/redis/issues/5577和 issuehttps://github.com/antirez/redis/issues/5544,期待redis官方在下个版本解决这两个问题。
从永久崩溃的消费者程序说起
前面已经介绍过消费者的pending消息队列,这个pending消息队列的主要作用是在消费者程序崩溃了,然后重新启动再次进行消费的时候,能够回溯自己已经获取但是还未通知消息被正确处理的消息列表,当然还有一个作用是能方便地我们观察目前有哪些消息“正在被处理”。
试想下面的情景,一个消费者程序所在的主机被雷电击中了,主机的硬件化成了灰烬,那么这个消费者程序再也无法启动了,这就是所谓的“永久性宕机”,如果发生这种情况,即使有消费者的pending消息队列也是无用的。那么stream如何处理这种特殊的情形呢?
stream提供了一种机制能够让一个消费者的pending消息队列中的消息的所有权(ownership)转移到另外一个消费者上面,这个机制使用XCLAIM命令实现
消费者pending消息队列中消息所有权的转移步骤
要想转移消费者pending消息队列中的消息,我们首先要能获取到这个消费者的pending队列,有什么方法呢?如果您还记得XREADGROUP命令的话,当该命令的ID参数不是特殊字符>时,其实就是在获取pending消息队列中的消息。但是这个办法明显是行不通的,因为消费者进程都永久死翘翘了,哪里还有使用XREADGROUP读取历史消息的机会,因此stream提供了更加方便的XPENDING命令来获取一个消费者分组或者消费者分组下面某个消费者的pending消息队列。
XPENDING key group [start end count] [consumer]
可以看到XPENDING和XRANGE命令非常类似,它们都提供了start end count参数,类似的,-和+这些特殊字符的含义也和XRANGE一样。
下面我们先看一下如何使用XPENDING获取整个消费者分组的pending的消息队列的概要信息
127.0.0.1:6379> XPENDING stream_fruit fruit_group
1) (integer) 4
2) "1542355421051-0"
3) "1542355444220-0"
4) 1) 1) "consumer_1"
2) "1"
2) 1) "consumer_2"
2) "2"
3) 1) "consumer_3"
2) "1"
当XPENDING只带key和group参数时,表示获取整个消费者分组的概要信息,这些信息包括:消费者分组的pending消息的总个数,pending消息队列中起始的消息ID和结束的消息ID,以及分组下面每个消费者的pending消息队列中消息的个数。
当XPENDING带上start end count参数时,这时会显示消费者分组pending消息的详情
127.0.0.1:6379> XPENDING stream_fruit fruit_group - + 10
1) 1) "1542355421051-0"
2) "consumer_1"
3) (integer) 4109624
4) (integer) 7
2) 1) "1542355427899-0"
2) "consumer_2"
3) (integer) 3801615
4) (integer) 3
3) 1) "1542355436365-0"
2) "consumer_2"
3) (integer) 3801615
4) (integer) 1
4) 1) "1542355444220-0"
2) "consumer_3"
3) (integer) 3786296
4) (integer) 1
其中显示的每条记录都包含下面的信息:消息ID;消息被哪个消费者消费了;消息自从被消费者获取后到现在逝去的时间,简称idle time(毫秒级别);消息被获取的次数,简称delivery counter。
其中idle time对转移消息所有权是非常重要的,它标识着这条消息自从被获取后已经有多久没有被正确处理了,如果idle time过长,那么很可能暗示着获取到该消息的消费者进程崩溃或者出现异常情况,此时才把它转移给其他消费者进行处理才是比较明智的选择。
XCLAIM key group consumer min-idle-time ID [ID ...][IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count][FORCE] [JUSTID]
#把consumer_2中的消息1542355427899-0所有权转移给consumer_1,并且当idle time > 1 Hour时才转移
127.0.0.1:6379> XCLAIM stream_fruit fruit_group consumer_1 3600000 1542355427899-0
1) 1) "1542355427899-0"
2) 1) "message"
2) "orange"
127.0.0.1:6379> XPENDING stream_fruit fruit_group - + 10
1) 1) "1542355421051-0"
2) "consumer_1"
3) (integer) 4311829
4) (integer) 7
2) 1) "1542355427899-0"
2) "consumer_1"
3) (integer) 16192
4) (integer) 3
3) 1) "1542355436365-0"
2) "consumer_2"
3) (integer) 4003820
4) (integer) 1
4) 1) "1542355444220-0"
2) "consumer_3"
3) (integer) 3988501
4) (integer) 1
#可以看到1542355427899-0这条消息已经被成功地转移到consumer_1的pending消息列表,并且您可能注意到1542355427899-0这条消息的idle time被重置了,在一条消息转移拥有权之后重置idle time是很有必要的,这个下面再说
#把consumer_2中的消息1542355436365-0所有权转移给consumer_3,并且当idle time > 10 Hour时才转移
127.0.0.1:6379> XCLAIM stream_fruit fruit_group consumer_3 36000000 1542355436365-0
(empty list or set)
#可以看到由于idle time不满足10Hour的要求,因此XCLAIM不会做任何的操作
刚才讲到,在一条消息的拥有权发生转移的时候,会把该消息的idle time重置,这样做是有原因的:防止该消息被重复消费。请看下面的场景
Client 1: XCLAIM stream_fruit fruit_group consumer_1 3600000 1542355427899-0
Clinet 2: XCLAIM stream_fruit fruit_group consumer_3 3600000 1542355427899-0
在很短的时间内,Client 1和Client 2 同时发现了消息1542355427899-0的idle time超时了,需要把该消息的拥有权转移给自己,如果在Client 1拿到改消息的拥有权之后,没有重置消息的idle time,那么Client 2的XCLAIM操作也会成功,那么这个时候就会出现有一条消息同时在consumer_1和consumer_3的pending消息列表中,这不但违反了消费者分组的定义,而且会造成消息重复消费,因此在XCLAIM操作成功后重置消息的idle time是预料之中的。
dead letter问题的处理
有了XCALIM之后,可以解决消费者进程因为永久崩溃导致的问题,但是在mq系统中还有另外一种特殊的情况称之为dead letter。由于某种原因,队列中插入了一条格式不合法的消息,因此我们的消费者程序无法正确处理它,这个时候即使有XCALIM也没有用,因为无论是哪个消费者进程对这条消息进行处理,总会失败。这个时候该怎么办呢。
你可能注意到前面讲XPENDING命令的时候会返回消息的一个特性:delivery counter。这个信息就是该消息被消费者获取到的次数(每使用XREADGROUP读取到该消息一次,这个消息的delivery counter就会增加1),因此我们可以通过该信息来做一些抉择:当发现一条消息的delivery counter大于某个阈值的时候,就说明这条消息不可能再被处理成功了,这个时候可以把这条消息从队列中删除,然后给管理员或者系统发送一条告警日志。这就是所谓dead letter的处理过程。
监控
stream专门提供了相关的命令来监控消息队列,毕竟这是一个成熟的mq系统必备的特性。我们可以使用XINFO命令来监控观测stream的方方面面。
XINFO [CONSUMERS key groupname]
[GROUPS key]
[STREAM key]
[HELP]
你可以使用XINFO从整体上观察一个stream的概要信息
127.0.0.1:6379> XINFO stream stream_fruit
1) "length"
2) (integer) 5
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "groups"
8) (integer) 1
9) "last-generated-id"
10) "1542355444220-0"
11) "first-entry"
12) 1) "1542355396362-0"
2) 1) "message"
2) "apple"
13) "last-entry"
14) 1) "1542355444220-0"
2) 1) "message"
2) "strawberry"
可以看到stream_fruit消息队列目前共存储5条消息,为了存储这5条消息(使用radix tree数据结构来存储),还记得stream中消息的格式吗,每个消息都是【field1 string1 field2 string2 …】这种格式,在stream_fruit中,fields总共有1个(因为这些消息的所有的field都是“message”嘛),存储这5条消息工占用了2个radix-tree节点。消息队列中的第一条消息的ID是1542355396362-0,最后一条消息的ID是1542355444220-0。
你还可以查看一个stream的消费者分组的概要信息
127.0.0.1:6379> XINFO groups stream_fruit
1) 1) "name"
2) "fruit_group"
3) "consumers"
4) (integer) 3
5) "pending"
6) (integer) 4
7) "last-delivered-id"
8) "1542355444220-0"
可以看到stream_fruit共有一个消费者分组fruit_group,该分组下面有3个消费者,目前该分组共有4个消息正在被处理(pending消息队列),该分组下次读取消息的起始位置是1542355444220-0。
你还可以查看消费者分组下面的消费者的概要信息
127.0.0.1:6379> XINFO CONSUMERS stream_fruit fruit_group
1) 1) "name"
2) "consumer_1"
3) "pending"
4) (integer) 2
5) "idle"
6) (integer) 10241230
2) 1) "name"
2) "consumer_2"
3) "pending"
4) (integer) 1
5) "idle"
6) (integer) 14228858
3) 1) "name"
2) "consumer_3"
3) "pending"
4) (integer) 1
5) "idle"
6) (integer) 3002029
可以看到fruit_group消费者分组下面共有consumer_1、consumer_2、consumer_3这三个消费者。以及每个消费者的pending消息队列的长度,以及每个消费者pending消息队列中最小的idle time。
构建一个stream监控系统
可以看到stream提供的XINFO命令是逐层递进的,我们可以很简单的就能构建一个使用stream作为mq的监控系统
- 首先使用XINFO stream key来获取消息队列的概要信息,我们能够得到stream的消息数量以及消息的起始和结束位置等信息
- 然后使用XINFO groups key来获取stream中消费者分组的信息,我们能够得到所有的消费者分组,以及每个分组中的消费者数量
- 根据每个消费者分组,使用XINFO CONUSMERS key group_name获取每个消费者的pending消息队列长度等信息
- 配合XPENDING命令 XPENDING key group_name - + count 10 consumer_name来循环遍历每个consumer的pending消息队列,从而能够获取每个消费者正在进行消费的消息列表
- 配合XPENDING的返回信息idle time和delivery counter,根据我们设置的阈值,我们可以对消息进行所有权转移以及触发dead letter等流程
上述流程非常清晰,并且实现简单,一个功能强大的监控系统呼之欲出。
定长消息队列的实现
stream支持定长消息队列(capped stream),有2种方式可以实现定长消息队列
- 在添加消息的时候使用MAXLEN参数
XADD mystream MAXLEN ~ 1000 * ... entry fields here ...
其中,~参数有特殊的含义,它表示这个stream的size大约等于MAXLEN,而不是刚刚好就是MAXLEN,指定了~之后,能够保证队列的最大容量不小于MAXLEN,如果MAXLEN=1000的话,那么这个capped stream的大小可能是1010,1020,1030等,但是也不会超出1000很多。
为什么会有这么奇葩的操作呢?原因是这样的:首先stream中的消息是使用radix tree来组织的,为了节省内存,stream使用了“大节点”的概念,什么是大节点呢,就是stream会把若干的消息进行编码,然后放在一个radix tree的节点中,这一组消息用一个macro node来表示,因此在stream的内部,并不是一条消息就用一个节点表示,相反的,是用一个大节点存放若干条消息,那么这个大节点能够存放多少条消息呢,可以在redis的配置文件中进行配置
# Streams macro node max size / items. The stream data structure is a radix
# tree of big nodes that encode multiple items inside. Using this configuration
# it is possible to configure how big a single node can be in bytes, and the
# maximum number of items it may contain before switching to a new node when
# appending new stream entries. If any of the following settings are set to
# zero, the limit is ignored, so for instance it is possible to set just a
# max entires limit by setting max-bytes to 0 and max-entries to the desired
# value.
stream-node-max-bytes 4096
stream-node-max-entries 100
因此如果精确地支持MAXLEN的定长队列,代价是巨大的,因为大节点的粒度比较粗,如果通过一条消息一条消息的删除,会牵涉到对大节点的各种更新操作,比如在大节点中查找某条消息,然后把其标识为删除,对于redis这种高性能的服务来说这是不可接受的,因此才引入了~这个类似“approximate”的参数,那这个大约的范围是多少呢,显而易见,在做消息的剔除的时候stream使用整个大节点剔除的方式,因此这个大约的范围就是:一个大节点能够存放多少条消息的数量,默认是100。
- 对一个正常的stream使用XTRIM命令
XTRIM key MAXLEN [~] count
该命令和使用XADD带上MAXLEN参数的效果一样。XTRIM是一个很有野心的命令,它被设计成可以支持多种策略来进行stream的裁剪,可是目前只支持MAXLEN策略,希望随着redis版本的演进,这个XTRIM能够大焕光彩。
消息的删除
上面讲了那么多,其实没有提及如何删除一条消息,目前可以通过而且只能通过XDEL命令从stream中“彻底”删掉一条消息
XDEL key ID [ID ...]
这个命令比较简单,不再详述。值得注意的是,由于大节点的存放方式,在使用XDEL删除一条消息的时候,有时候并不会释放内存,只有等到这个大节点中所有的消息都被删除的时候才会真正的释放内存。
到了这个地方stream的所有特性基本上都已经介绍完了,希望通过上面的介绍你已经能够熟练地使用stream来做一个mq系统了。
性能
前面讲了那么多,那么stream的性能到底如何呢。下面我们就拿stream和disque做了一部分性能测试,结果如下
测试环境
| OS | 内核 | CPU | MEM | 部署方式 | 网络 |
|---|---|---|---|---|---|
| CentOS | Linux release 7.4.1708 (Core)3.10.0-693.17.1.el7.x86_64 | Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz 4核 | 4GB | docker(18.02.0-ce) | net=host |
数据插入性能测试
- 数据插入格式:从某个项目中实际终端上报的5D数据中随机挑选一条并插入
- 数据量大小:4GB内存最多能够存放150W条左右,因此我们测试的数据量为150W
- 插入方式:利用redis和disque的pipleline特性每次插入1000条数据
| 服务 | 数据量 | 插入方式 | 耗时 | CPU(Avg) | MEM(total) |
|---|---|---|---|---|---|
| Redis(stream) | 150W | pipline(1000) | 13.976834706s | 90%-95% | 91.3% |
| disque | 150W | pipline(1000) | 28.851797631s | 85%-90% | 88.3% |
数据消费性能测试
-
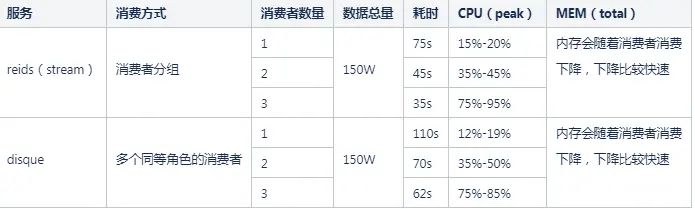
场景:150W的数据已经生产完毕,使用不同数量的消费者进行消费测试
-
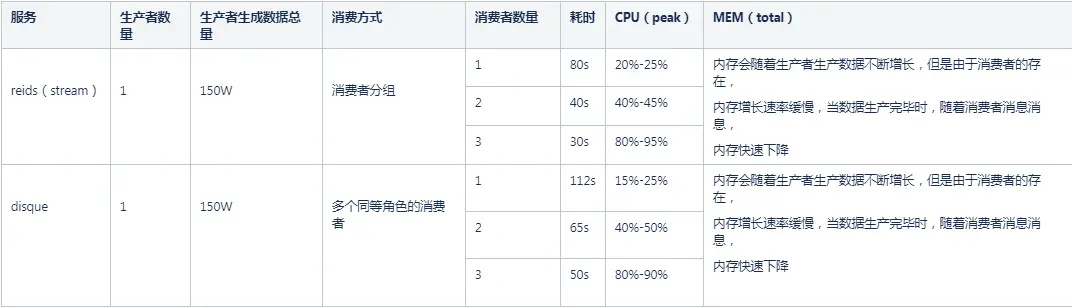
场景:数据没有事先生成,使用1生产者+N个消费者同时进行数据的生成和数据的消费工作,其中生产者生成数据的总量是150W
结论
从上面可以看到stream相比于disque无论在写数据还是读数据的操作上都有长足的进步,stream的性能大概是disque的1.5-2倍之间。另外由于stream消费者分组逻辑上的功能划分,减少了消费者之间的数据竞争,可以看到在一定范围内,消费的速度和消费者的数量成正比关系。
disque和stream的优缺点
disque的缺点
- 最大的缺点是项目活跃度不高,目前长期处于无人维护的状态,碰到的BUG需要自己填坑
- 相比于stream效率不高,原因也很简单disque的框架代码没有经过优化
disque的优点
- 是一个真正的分布式服务,摒弃了redis cluster的各种奇葩的限定,理论上只要有机器消息队列可以无限水平扩展
stream的缺点
- stream的缺点就是在redis内部,stream就是一个单一的key,如果不对key进行分片,那么stream的容量被限制在单个redis的实例,当然我们可以使用redis cluster对stream的key进行分片,实现类似kafka多partition的概念,但是由于redis cluster的一些限制,需要解决redis原生命令不支持跨slot操作的问题,当然经过合理的设计,这并不是一个很大的问题,但是也需要解决,因此如果mq中的数据过于庞大,单个redis实例已经无法容纳,我们需要对stream的key进行分片并解决一些问题,这增大了业务实现的难度
stream的优点
- stream之所以被发明出来就是要解决redis作为mq系统应用的痛点问题
- stream是redis5.0引入的重要数据结构,他的稳定性和可用性随着版本的发布肯定会越来越好,这一点是可以得到保证的
- stream相对disque效率要高
作者:Flame_1109
链接:https://www.jianshu.com/p/e5751c2ac9c8
来源:简书